



The "AI Outperforms Doctors" Claim Is False, Despite NYT Story - A Rebuttal (Part 2 of 6)
The NYT story citing the JAMA study is fake. I'm sorry, but as a peer reviewer, I wouldn't let this study pass my desk for one main reason: the sample size of 6! You've got to be kidding me, JAMA.


Welcome to AI Health Uncut, a brutally honest newsletter on AI, innovation, and the state of the healthcare market. If you’d like to sign up to receive issues over email, you can do so here.
Disclaimer: The opinions expressed here are solely my own and do not represent those of any sponsors, advertisers, or supervisors. Oh, wait—I don’t have any. 😂
I’m honored to have been invited as a guest writer to contribute this article to the next edition of Artificial Intelligence Made Simple, a renowned Substack publication that covers everything you need to know about hot topics in AI and the intricacies of machine learning models, written by the respected expert and star author, Devansh. I encourage all of you to visit and subscribe to Artificial Intelligence Made Simple.
Shame on JAMA for publishing this study, and even more shame on The New York Times for amplifying it. The reason the scientific community largely ignored this study—published four weeks ago—until The New York Times gave it a platform is simple: the study isn’t scientifically valid.
But let’s start at the beginning.
Stanford researchers published a study in the Journal of the American Medical Association (JAMA) on October 28, 2024, with the primary goal of evaluating diagnostic reasoning—not the final diagnosis (I’ll explain this important distinction below!)—of physicians with and without access to a Large Language Model (LLM), specifically ChatGPT-4. As a secondary finding, the authors reported that the LLM alone outperformed both physicians without and with LLM access by 18% and 16%, respectively. This secondary result has since sparked a whirlwind of attention, but I argue throughout this article that it is not scientifically valid.

Worst of all, the New York Times, in a classic game of “broken telephone,” misinterpreted the secondary finding, completely missing the point that the study focused on diagnostic reasoning, not diagnosis itself! On November 17, 2024, they published an article with the sensational—and utterly misleading—headline: “A.I. Chatbots Defeated Doctors at Diagnosing Illness.”
Predictably, after the New York Times article, social media amplified this faulty conclusion to a fever pitch, filling inboxes everywhere and even distracting Elon Musk from his Mar-a-Lago escapades. 😊
This unfortunate chain reaction could have been avoided. As I’ll thoroughly explain in this article, the story has 5 major flaws (plus a few additional important issues I detail in Section 5). Here’s a breakdown:
The JAMA study’s sample size was 6 (yes, six).
That’s not just small—it’s laughably inadequate for drawing any valid conclusions.The study and the New York Times headline are talking about two different things.
The actual study focused on diagnostic reasoning, not the ability to accurately diagnose an illness. Big difference. Oops.The study uses a subjective weighted formula to evaluate outcomes on an 18-point scale.
The paper never scientifically justifies its weighting decisions, leaving the methodology feeling arbitrary and unconvincing.The physicians weren’t properly trained to use AI tools.
This omission severely undercuts any conclusions about how AI might augment human diagnostic capabilities.The study fails to reflect the real-world complexity of medical diagnosis.
Medical diagnosis is nuanced and involves far more than just reasoning through test cases. The study’s design doesn’t capture this reality.
Initially, I planned to include this critique as part of Part 3 in my comprehensive Substack series, “The ‘🤖machines will replace doctors👩🏽⚕️’ debate turns 70!” However, this study demands a standalone analysis or at least some immediate clarification. Why? Because too many smart people have been misled into believing this study has merit. The New York Times jumping the gun only made things worse. Furthermore, their coverage failed to accurately convey the study’s actual findings.
If you’re new here, I recommend you start with Part 1 of my series, which explores the early algorithms from 70, 60, 50, and 40 years ago—all attempts to replace clinicians’ work that ultimately fell short.
Here’s the TL;DR:
1. The Notorious JAMA Study: A Sample Size of 6 😊
2. How to Address Small Sample Bias: My Recommendations
3. NYT — A Broken Telephone
4. Even with ChatGPT-1o: AI Still Falls Short in Medical Reasoning
5. Additional Problems with the JAMA Study Beyond Small Sample Size Bias
5.1 Problems with Study Design and Methodology
5.2 Problems with Results and Interpretation
5.3 Problems with Real-World Applicability
6. Silver Linings
7. The Bigger Publishing Crisis: Fake Data and Clickbait Studies
8. Conclusion
1. The Notorious JAMA Study: A Sample Size of 6 😊

A study published in JAMA on October 28, 2024, by Stanford researchers reported findings from a randomized clinical trial involving 50 physicians. The trial concluded that incorporating an LLM such as ChatGPT-4 alongside conventional resources (referred to as “physicians + LLM”) did not significantly improve physicians' diagnostic reasoning performance. However, the study claimed that LLM alone outperformed both physicians and the combination of physicians + LLM by a statistically significant margin of 16%-18% in accuracy. Specifically, the LLM achieved 92% accuracy in diagnostic reasoning (not diagnosis, as erroneously reported by The New York Times), compared to 74% for physicians and 76% for physicians + LLM.
Note: “Diagnostic reasoning” refers to the cognitive process by which a clinician gathers, interprets, and integrates information to arrive at a differential diagnosis, considering various possibilities and weighing supporting and opposing evidence. “Diagnosis”, on the other hand, is the final conclusion reached after this reasoning process, identifying the specific condition or disease affecting a patient. While diagnostic reasoning encompasses the dynamic and iterative steps involved in evaluating symptoms, tests, and patient history, diagnosis represents the static end point of this analysis. The JAMA study under consideration attempts to highlight how tools like LLMs can influence diagnostic reasoning without necessarily changing the quality or accuracy of the diagnosis itself.
Here’s a critical detail that was conspicuously omitted from the journal abstract:
The study evaluated performance on only 6(!) hand-picked medical cases (vignettes).
Note: A “vignette” refers to a structured and concise description of a clinical case, which is designed to simulate real-life scenarios for educational or research purposes. These vignettes typically include patient history, physical examination findings, and laboratory results. In the JAMA article under consideration, vignettes are designed to test diagnostic reasoning by presenting complex and varied medical situations, avoiding overly simplistic or excessively rare cases.

How did this study pass the JAMA editorial review process?
I dedicate an entire chapter in my recent paper to discussing this peculiar phenomenon: standards for statistical power that would be deemed laughable in fields like statistics or economics are readily accepted in medicine. This is baffling, especially given that human health and lives are at stake. Can someone please explain this anomaly?
In my paper, I highlighted an example of a peer-reviewed study that used 28 vignettes to evaluate which digital symptom checker was superior—a sample size I thought was absolutely absurd. Yet, here we are with a study based on 6! And they were hand-picked, no less.
A sample size of 6 is as good as a rumor, from a statistical standpoint.
What’s interesting is that the original NEJM dataset contained 105 vignettes. Yet, since it seems the 50 physicians involved gave the authors only one hour of their time each, the authors cherry-picked just 6 out of the 105 vignettes. 6? Really?

I’ll let the authors defend themselves, but this feels fishy. I don’t care if the rationale for selecting these 6 was the “greatest ever” — they dropped 94% of the sample!
There’s likely a reason the authors avoided using the full dataset. Maybe the majority of the vignettes were “too easy,” and they thought those wouldn’t show meaningful differences. Or maybe 94% of the vignettes were “too messy” to deal with. Whatever the real reason, readers deserve transparency. Frankly, the paper offers none. Tossing out 99 out of 105 vignettes without a clear explanation leaves a glaring question mark that the authors failed to address.
The authors claim they selected these 6 vignettes based on “case selection guidelines,” which prioritized a broad range of pathological settings, avoided overly simplistic cases, and excluded exceedingly rare cases. Fine. But then these hand-picked vignettes were further “refined” by replacing Latin medical terms (like livedo reticularis) with layman-friendly phrases (like “purple, red, lacy rash”).
What the heck is going on here? The lack of clarity and the sheer level of curation make this whole process feel... off.
2. How to Address Small Sample Bias: My Recommendations
Now, let me switch to my peer reviewer hat and pose a critical question:
Why not utilize the full sample of 105 vignettes? While the constraint of assigning a maximum of 6 vignettes per physician may not be ideal, it’s still possible to leverage the entire dataset using good ol’ statistics. Two straightforward methods come to mind:
Random Sampling with Overlap: Randomly and uniformly draw 6 vignettes for each doctor from the full sample of 105. With 50 doctors and only 105 vignettes, overlaps are inevitable—and actually desirable. Overlapping assignments allow comparisons between diagnoses for the same vignettes across different physicians, providing a foundation for robust analysis.
Balanced Incomplete Block Design (BIBD): Alternatively, implement a BIBD or a similar design to ensure balanced vignette assignments. Each vignette is reviewed by an equal number of doctors (e.g., 2 or 3), while each doctor reviews no more than 6 vignettes, adhering to the constraint. This design ensures overlap between doctors’ vignette assignments, facilitating comparisons and enabling statistical adjustments for vignette difficulty. Mixed-effects models or Analysis of Variance (ANOVA) could then be used to account for variability attributable to both doctors and vignettes.
These techniques—and likely others—would allow researchers to retain the diversity of the full sample while improving the statistical rigor of the analysis.
That said, the authors likely had reasons for discarding 94% of the vignettes. It would be helpful to understand their rationale.

More importantly, using the entire sample of 105 vignettes is crucial for a fair comparison with the LLM. The LLM was run 3 times per vignette to increase the number of observations to 18, but these were drawn from the same limited sample of 6 vignettes! This small (let’s be real—minuscule) sample size compromises the validity of any comparison and undermines the potential insights that could have been drawn from a broader, more representative sample.
It’s important to note that the authors of the JAMA study “try” (I’ll explain the quotation marks below) to account for “the uncertainty from the number of cases” and the repeat prompting of the LLM by using a random effects model. This leads them to the faulty conclusion that statistical estimates already address the small (or more accurately, minuscule) sample bias.
Here’s my reaction:
Any freshman majoring in statistics could tell you it’s an absolute taboo to apply a random effects model to a dataset with just 6 cases.
There is nothing random about a sample size of 6. (And in this study, that number turned out to be even lower—only 4–5 cases per physician.) Even if those 6 cases were spread across 50 physicians (or even 500 physicians), the confidence intervals would still be way too optimistic. Why? Because you kept your sample size absurdly small. No statistical estimation model, no matter how sophisticated, can estimate the variability of your results when there’s practically no data to “vary” against.
There’s no magical statistical bullet for an absolute lack of data.
3. NYT — A Broken Telephone

The authors of the JAMA study blurred the line between diagnostic reasoning and the actual diagnosis, leaving room for misinterpretation. Naturally, The New York Times ran with the story without clarifying this nuance. Like a classic game of broken telephone, the distinction vanished—reasoning was magically equated to diagnosis, and voilà, AI was crowned a better diagnostician than doctors.

In reality, the accuracy score for the vignette cases overwhelmingly measured reasoning (78%), not the final diagnosis. The weight of the actual final diagnosis was a mere 2 out of 18 (11.1%) or 2 out of 19 (10.5%) of the total score, depending on the vignette.
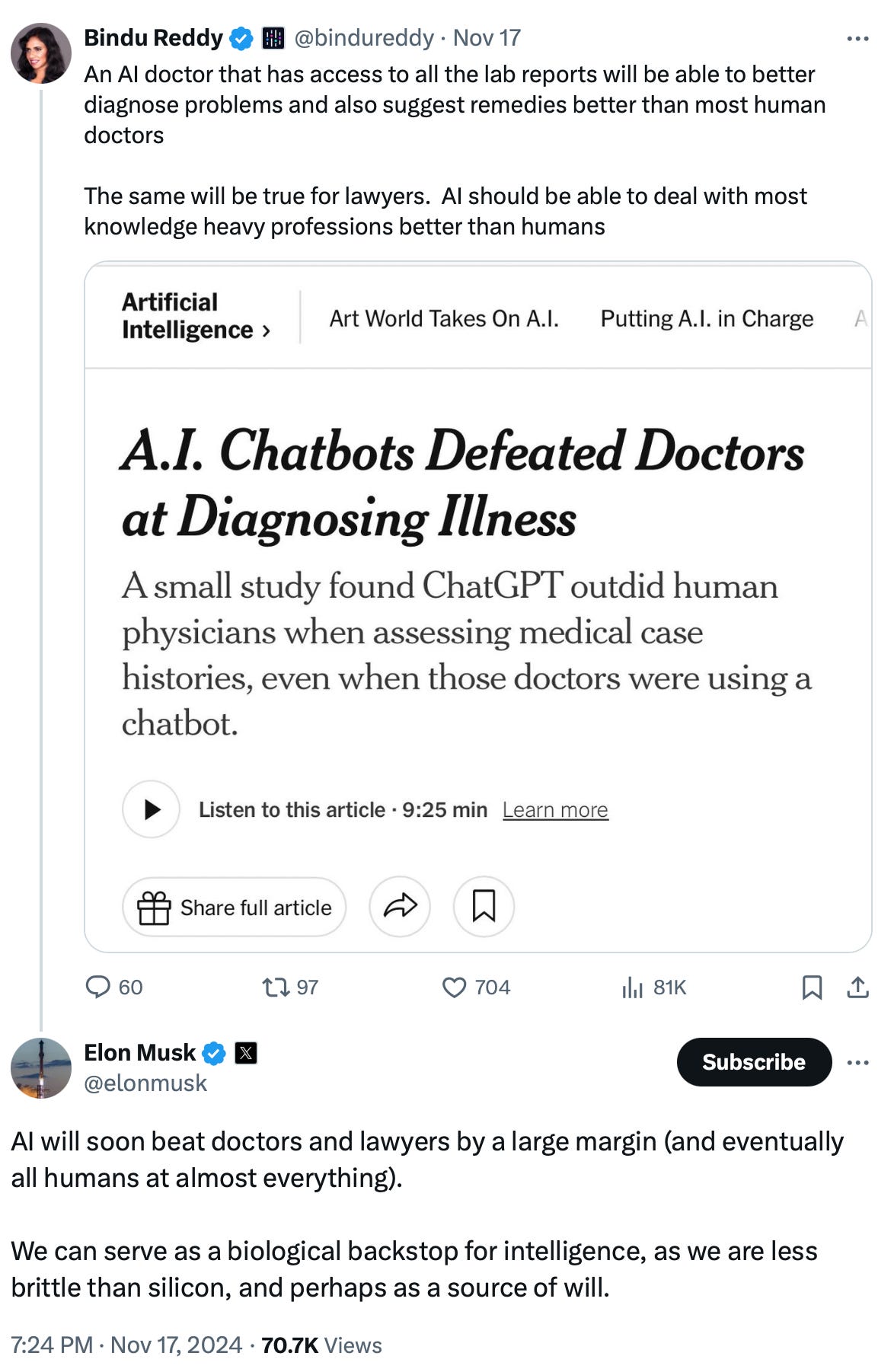
Of course, the NYT piece caught fire, spreading to every corner of Earth—and apparently Mars—where even Elon Musk joined the chorus. Like most humans (myself included), Musk doesn’t mind quoting “enemy media” when it confirms his biases. 😉
4. Even with ChatGPT-1o: AI Still Falls Short in Medical Reasoning
My colleague
and I, along with many other researchers, have extensively documented the flaws in ChatGPT-1o and its exaggerated claims of medical diagnostic supremacy. We’ve written pieces like “Selling the New o1 ‘Strawberry’ to Healthcare Is a Crime, No Matter What OpenAI Says 🍓” and “A Follow-Up on o1’s Medical Capabilities + Major Concerns About Its Utility in Medical Diagnosis.”So, when I came across this JAMA study showcasing a model from two generations prior, my reaction was, “I better check this out.”
Here’s the thing about AI reasoning:
ChatGPT is getting really good at reasoning. In fact, it reasoned so convincingly that the Earth is flat, I’m starting to have my doubts. 😉
5. Additional Problems with the JAMA Study Beyond Small Sample Size Bias
I don’t want to turn this into a never-ending article, but here’s a brief overview of other potential issues with the JAMA study. Some were acknowledged by the authors themselves, while others were flagged by experts like Graham Walker, MD, Jung Hoon Son, MD, and Dr. Terence Tan:



5.1 Problems with Study Design and Methodology
1️⃣ No Benchmark is No Better Than a Poor Benchmark:
In my numerous critiques, including my review of the Med-Gemini model, one recurring issue I’ve highlighted is the widespread problems with traditional medical benchmarks like MedQA/USMLE and MMLU. As I recall, this was a central critique in at least 4 other studies claiming AI dominance over physicians + LLM, a point emphasized by
. Now, this JAMA study doesn’t use any benchmark whatsoever, and I don’t think that’s a good thing. 😉 The way performance was rated—particularly how scores were assigned for Reasoning, Diagnosis, and Additional Steps—and how those factors were weighted seems highly subjective and ambiguous. Why was an 18-point scale used, and why did it sometimes appear to be a 19-point scale? Why was reasoning weighted at 78% while the final diagnosis was weighted at only 11% of the overall importance? These decisions raise a lot of questions…
2️⃣ Subjectivity in Evaluation:
The grading relied on blinded expert consensus but included subjective elements like reasoning quality and appropriateness of supporting factors, which could introduce evaluator bias.
3️⃣ Physician Selection Bias and Case Selection Bias:
Physician Bias: The JAMA study included only physicians with a median of 3 years of practice (range 2 to 8), not representing the broader U.S. physician population, which averages over 20 years of practice. (According to the Journal of Medical Regulation, the mean age of licensed physicians in the U.S. is 51.9 years, suggesting that licensed physicians have been practicing for at least 20 years, on average.)
Case Bias: The hand-picked clinical vignettes were intentionally complex and atypical, not reflecting a realistic caseload that includes a mix of simple, common, and rare cases.
4️⃣ Vignette Misclassification Bias:
Although the authors claimed to select the six vignettes based on “case selection guidelines” aiming for a broad range of pathological settings while avoiding overly simplistic and exceedingly rare cases, they further refined these hand-picked vignettes by replacing Latin medical terms with layman-friendly phrases. For example, “livedo reticularis” was changed to “purple, red, lacy rash.” This alteration could impact the diagnostic process by simplifying medical terminology that physicians typically use, potentially skewing the results.
5️⃣ (Mis)Use of Standardized Vignettes and Textual Data:
The reliance on structured, text-based vignettes does not correspond to real-life clinical scenarios, which involve patient interaction, physical examination, and continuous data collection. LLMs depend entirely on textual input and cannot incorporate visual, physical, and contextual cues essential for accurate diagnosis.
6️⃣ Challenges in Real-World Data Collection:
According to Dr. Jung Hoon Son, the JAMA study overlooks the complexities of real-world data gathering, such as validating lab and imaging results and dealing with incomplete or messy patient data. Errors and artifacts often complicate diagnostics, which are streamlined in controlled vignettes.
7️⃣ Time Constraints and Allocation:
Physicians were given a fixed amount of time to complete cases, which may not reflect real-world diagnostic timelines.
8️⃣ Physician Training and Familiarity with LLMs:
Physicians were not trained in using LLMs, potentially affecting their ability to integrate these tools effectively. Experts like Dr. Graham Walker note a systemic gap in LLM literacy among clinicians, impacting the JAMA study’s applicability.
5.2 Problems with Results and Interpretation
9️⃣ Negligible Improvement with LLM Assistance:
No statistically significant improvement was observed in diagnostic reasoning scores when physicians used the LLM, questioning the utility of these tools as adjuncts in their current form.
🔟 Over-Reliance on Knowledge Regurgitation:
According to Dr. Jung Hoon Son, the LLM’s performance relies on regurgitating encyclopedic information. While effective in structured prompts, it lacks the ability to gather and synthesize new information in real-time, limiting its applicability to actual patient care scenarios.
1️⃣1️⃣ Misalignment with Clinical Decision-Making:
In his summary, Dr. Terence Tan calls the JAMA study a “great big nothing,” pointing out that the LLM’s structured diagnostic approach does not align with the fluid and ambiguous nature of real-world clinical decision-making, which often requires contextual judgment and adaptability.
1️⃣2️⃣ Media Oversimplification and Overhype:
Media narratives have oversimplified the study’s findings, suggesting that “text-prompts + LLM = diagnosis,” overlooking the complexities of diagnostic reasoning. Experts like Dr. Graham Walker and Dr. Terence Tan caution against overhyping the results without considering practical limitations.
5.3 Problems with Real-World Applicability
1️⃣3️⃣ Integration and Training Gaps:
Health systems may struggle to integrate LLMs effectively without adequate physician training or workflow redesign. The generational gap and lack of familiarity with Generative AI (GenAI) tools among clinicians pose additional challenges.
1️⃣4️⃣ Liability, Ethical, and Economic Concerns:
Deploying LLMs independently raises ethical and liability issues. LLMs lack the ability to contextualize diagnostics within resource constraints and ethical principles like Occam’s Razor, critical aspects of modern healthcare. As I always say, Doctors Go to Jail. Engineers Don’t.
1️⃣5️⃣ Risk of Overdiagnosis in Simple Cases:
LLMs might overanalyze straightforward cases, leading to unnecessary testing or patient anxiety.
1️⃣6️⃣ Dependence on Pre-Structured Data:
Dr. Jung Hoon Son points out that by benefiting from pre-collected, neatly structured case reports, LLMs sidestep the bottleneck of clinical workflows—effective collection and interpretation of incomplete or messy patient data.
6. Silver Linings
While the JAMA study didn’t convince me of the validity of its results, hypothetically, I wouldn’t be surprised if AI is becoming better than doctors. And that’s exactly what I’ll be exploring in fine detail in in Part 3 of this series, coming in the next few weeks.
There’s no denying that an advanced LLM can handle complex cases with a level of thoroughness that might reduce the risk of missing critical details.
In the real world, asking a physician to handle 6 complex cases in just one hour—spending only 10–12 minutes per case—seems almost impossible. Balancing speed with accuracy, and, in the case of LLM assistance, figuring out how to interrogate the model effectively, doesn’t reflect standard practice—yet. However, in fast-paced environments like the ER, such a scenario could be more plausible—and perhaps this is where AI should shine brightest.
There is no question that AI can enhance physicians’ work. In that regard, I feel it’s important to address a critical implication if the JAMA study results about the LLM's standalone performance are valid—and that’s a big “IF.”
Assuming (again, a BIG assumption, which was not validated in the study, as I explain in this piece) that LLMs truly outperform human doctors by 18% in diagnostic accuracy, as the JAMA study claims, the industry faces a pivotal opportunity. Physicians must embrace collaboration with LLMs and other AI tools, educating themselves on how these tools can complement their expertise. This includes learning how to interact effectively with LLMs (e.g., designing more precise prompts) and, to the extent possible, understanding the reasoning behind the model’s diagnostic suggestions.
By adopting these practices, doctors could significantly improve their diagnostic accuracy while also gaining deeper insights into diagnostic reasoning. This collaborative approach might even reveal treatment options they hadn’t previously considered. Trusting and leveraging AI tools like LLMs could not only elevate clinical outcomes but also foster ongoing learning and innovation in the practice of medicine.
Here’s more good news: the JAMA study relied on the ChatGPT-4 model, which became outdated on May 14, 2024—two generations ago. ChatGPT-4o is significantly better than ChatGPT-4, and for reasoning (the crux of this study, as I mentioned earlier), ChatGPT-1o is state-of-the-art (SOTA) today. Built specifically for reasoning, it’s designed to surpass the capabilities of its predecessors—though, as I mentioned earlier, it is far from perfect.
7. The Bigger Publishing Crisis: Fake Data and Clickbait Studies
There’s a much bigger problem at play here. Publishing is the only industry where the suppliers of the core product—authors—are penalized with massive manuscript submission fees instead of being rewarded for their work. But the publishers are oligopolies, and they know the power they hold. As a researcher, if you want to advance your career, you have no choice but to play their game. So they exploit the system: raising submission fees, banning authors from submitting to multiple journals simultaneously, restricting researchers from sharing their own work during peer review, refusing to pay reviewers (because “prestige” is supposed to be compensation enough), and imposing countless other absurd policies.
This is the crux of the antitrust lawsuit recently filed in the U.S. District Court for the Eastern District of New York against six of the largest academic publishers.
These unfair practices create a perverse feedback loop. Reviewers, unpaid and undervalued, lose motivation. They stop taking their role seriously because, after all, there are no consequences for doing a bad job. Mistakes slip through. Editors, often lacking the specific expertise needed to evaluate highly specialized studies, fail to catch these errors. The result? An increasing number of papers with questionable or outright “fake” findings make it to publication. This, in turn, incentivizes authors to cut corners. Why spend two years and $100,000 rigorously testing and validating a study when you can produce a publishable result in two months for $1,000 with minimal effort or scrutiny?
Enter the mass media, which amplifies the problem. Journalists, chasing clicks and virality, don’t—or can’t—take the time to verify a study’s validity. Integrity takes a back seat to sensationalism because what drives advertising revenue isn’t accuracy, it’s engagement. Clickbait headlines and flashy findings rule the day.
It’s a wicked chain reaction.
This dysfunction is part of why we’re not seeing comprehensive AI studies in medicine. The journal review process takes months, but AI advances at lightning speed. By the time a study is published, it’s often outdated. And when people like me point out its irrelevance, researchers are left asking themselves: “Why bother?” The result? A proliferation of superficial, “fly-by-night” reports. For anyone with a shred of academic integrity, this is profoundly discouraging.

Clickbait and flashy findings also fuel data manipulation and outright fraud. Take the recent Harvard Business School debacle, which escalated into a full-blown fraud investigation. The rewards for authors with attention-grabbing results are enormous: consulting gigs, lucrative speaking fees, and cushy academic salaries. Starting pay at business schools can hit $240,000 a year—double what many campus psychology departments offer.
As Dr. Jeffrey Funk aptly observes:
“This is really an indictment of social science research because this explanation is applicable to many social science research disciplines. The fact is that flashy conclusions, including hyping AI, can lead to consulting gigs and speaker’s fees while crazy theories, easy data manipulation, and “more cheating and hype leading to more cheating and hype” are common in many research disciplines.”
The incentives are broken, and the fallout isn’t just academic—it’s societal.
8. Conclusion
Let’s get our sh*t together in academia. Why are we acting like teenagers chasing likes and crafting clickbait headlines? Have we forgotten what scientific integrity means?
This isn’t about whether AI is better than doctors. For all I know, the next time I have a proctology exam, an AI might tell me to “just relax.” 😉
What this is about is getting the facts straight.
Sure, maybe the JAMA study results will eventually hold water. But validity requires a foundation of facts, not a sample size of 6. Six isn’t science. It’s a footnote in a brainstorming session.
We need a scientifically robust study that compels the clinical community to say, “You know what? That’s solid research. Great job.” Until then, this debate will continue to swirl aimlessly.
Oh, and as I’ve been saying for years: even if AI achieves 99.999% accuracy in medicine—whatever that means—it still wouldn’t matter until we define liability and responsibility for its use in healthcare, both within and outside the boundaries of “standard of care.” Precision is pointless if we haven’t sorted out who takes the fall when things go wrong.
And let’s not gloss over the larger issue here: the rise of fake publications and clickbait studies. It’s become a stain on academia, turning science into a popularity contest instead of a pursuit of truth.
We need to bring ethics and professionalism back to science. That’s the only path to meaningful progress.
I invite the authors of the JAMA study to join the conversation. Let’s have a productive, fact-based discussion. And if I’ve crossed a line or botched my review of the study, I’ll own up to it. At the end of the day, I’m just a guy from a third-world country, sitting in a cold, smelly basement, trying to make sense of it all. What do I know, right? 😉
All right, that’s a wrap.
As a reminder, Part 1 of this mini-series explored the rich history of the “🤖 Machines will replace doctors 👩🏽⚕️” debate—which just turned 70!
Part 3 is my rebuttal to the New York Times op-ed by
, M.D., of Scripps Research, and , Ph.D., of Harvard University, challenging their implication that AI doctors may be more accurate than human doctors.Also, don’t miss Part 4 of this series—a super deep dive and probably the most comprehensive breakdown of Why AI Will Replace Doctors—coming in the next few weeks. Bad news for doctors. Great news for engineers. Stay tuned.
Acknowledgment: This article owes its clarity, polish, and sound judgement to the invaluable contributions of Rachel Tornheim. Thank you, Rachel!
👉👉👉👉👉 Hi! My name is Sergei Polevikov. In my newsletter ‘AI Health Uncut’, I combine my knowledge of AI models with my unique skills in analyzing the financial health of digital health companies. Why “Uncut”? Because I never sugarcoat or filter the hard truth. I don’t play games, I don’t work for anyone, and therefore, with your support, I produce the most original, the most unbiased, the most unapologetic research in AI, innovation, and healthcare. Thank you for your support of my work. You’re part of a vibrant community of healthcare AI enthusiasts! Your engagement matters. 🙏🙏🙏🙏🙏
This “AI outperforms doctors” hoax has gone way too far. It's embarrassing that now CNN picked it up. They have 16 co-authors on the JAMA article, and apparently not a single statistician. To make it worse, they don’t even seem to know the numbers from their own study. All of a sudden, 92% accuracy has turned into 90%. It's just bizarre.
https://www.cnn.com/2024/11/27/health/video/ai-illness-diagnosis-study-rodman-intv-ebof-digvid