

Med-Gemini by Google: A Boon for Researchers, A Bane for Doctors
I've read all 58 pages of Google's latest paper on its new LLM for medicine, and I have low expectations. Here's my rebuttal.


Welcome to AI Health Uncut, a brutally honest newsletter on AI, innovation, and the state of the healthcare market. If you’d like to sign up to receive issues over email, you can do so here.
Yesterday, Google published a new paper on fine-tuning its state-of-the-art (SoTa) multimodal LLM, called Gemini, for medical purposes, aptly naming it Med-Gemini.
In this article, while acknowledging the achievements presented in the paper, I primarily offer a rebuttal. I’m curious to learn what the authors think about my critiques.
First, it’s important to note that there was another paper on a very similar topic titled “Gemini Goes to Med School: Exploring the Capabilities of Multimodal Large Language Models on Medical Challenge Problems & Hallucinations,” published by researchers from India in February 2024.
Second, I still can’t get over the fact that, true to Google’s tradition, the Med-Gemini paper lists 71(!) co-authors. Call me old-fashioned, but I find that excessive.
Third, I’m mesmerized by the ongoing race for what I call “theoretical” accuracy with new LLMs. However, there has been virtually zero progress in what I call “practical” accuracy.
The paper relies on traditional data benchmarks. Specifically, for text, it revisits the MedQA/USMLE dataset, a collection of over 12,000 questions from professional medical board exams.
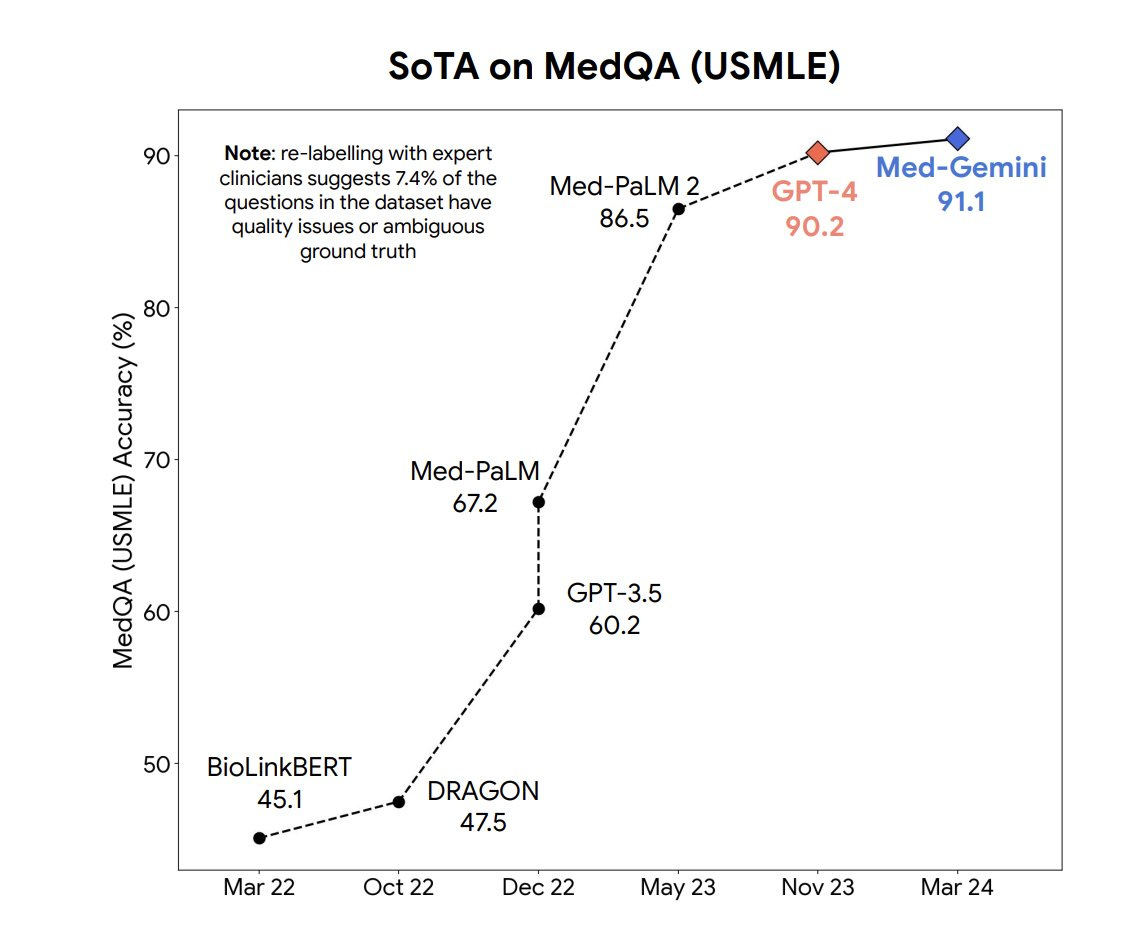
Med-Gemini performed exceptionally well on the MedQA, achieving 91% accuracy and surpassing its previous model, Med PaLM 2, by 5%, and GPT-4 by 1%. To be fair, GPT-4 is a general LLM that wasn’t fine-tuned on medical data, which I believe strongly demonstrates how crazy good GPT-4 is.
Med-Gemini showcased the effectiveness of multimodal medical fine-tuning and its adaptability to medical modalities such as electrocardiograms (ECGs) through specialized encoder layers. It also exhibited strong long-context reasoning capabilities, achieving state-of-the-art (SoTa) results on benchmarks like “needle-in-the-haystack” tasks in lengthy electronic health records (EHR) and benchmarks for medical video understanding.
This all sounds swell. However, I have a bone to pick with the authors of the paper.
My Major Concerns with Med-Gemini
➡️ I can’t blame Google for choosing “standard” medical benchmarks, and at this point, it is easier for them to conduct both time series and cross-sectional comparisons with the same benchmarks. However, two recent papers have developed “clinician-aligned” benchmarks. One of them showed that LLMs, fine-tuned on MedQA and other standard datasets, perhaps counterintuitively do worse on “clinician-aligned” benchmarks than even the original non-medical LLM. (Source: “MedAlign: A Clinician-Generated Dataset for Instruction Following with Electronic Medical Records”.)
➡️ Almost every paper by Google researchers concludes with a statement along the lines of “rigorous evaluation needed before real-world deployment”. Then why not do it? In my view, validating even not the most state-of-the-art model in a real-world clinical setting is far more important than this race for hypothetical theoretical dominance. Google is clearly picking the low-hanging fruit to add to this hype, in my opinion.
➡️ There is a major conflict of interest: the goal of Google researchers is to publish to advance their careers. Whether their AI models are usable in a real-world scenario is not their primary objective.
Bad Benchmarks, Bad Data, and Hallucinations
LLMs like Med-Gemini and GPT-4 have demonstrated expert-level performance on medical question-answering benchmarks including MedQA/USMLE and MMLU. However, these benchmarks employ multiple-choice, exam-style evaluations where question stems summarize key information and a single answer choice is best. It is not known if performance on these tasks will translate when a model is deployed in the complex clinical environments.
In particular, a study that was just published in NEJM AI by researchers at Mount Sinai found that four popular GenAI models still have a long way to go until they are better than humans at matching medical issues to the correct diagnostic codes. After having GPT-3.5, GPT-4, Gemini Pro, and Llama2-70b analyze and code 27,000 unique diagnoses, GPT-4 came out on top in terms of exact matches, achieving an accuracy of only 49.8%. (Source: Stat News.)
However, there are two “clinician-aligned” benchmarks, MedAlign and Zero-Shot Clinical Trial Patient Matching, both developed by researchers at Stanford University. Google’s Med-Gemini model hasn’t applied these benchmarks, but perhaps it should have.
I’m going to borrow some compelling arguments against benchmarking to MedQA from one of the co-authors of the MedAlign paper, Jason Alan Fries, as shared on X:
1️⃣ MedQA Doesn’t Reflect Realistic EHR Data.

MedQA comprises short-form, multiple-choice questions based on curated patient vignettes. This format is unlike the complex, messy data found in electronic health records (EHR).
2️⃣ Clinicians are looking for something practical that works for retrieving and summarizing data. MedQA is misaligned with those needs.
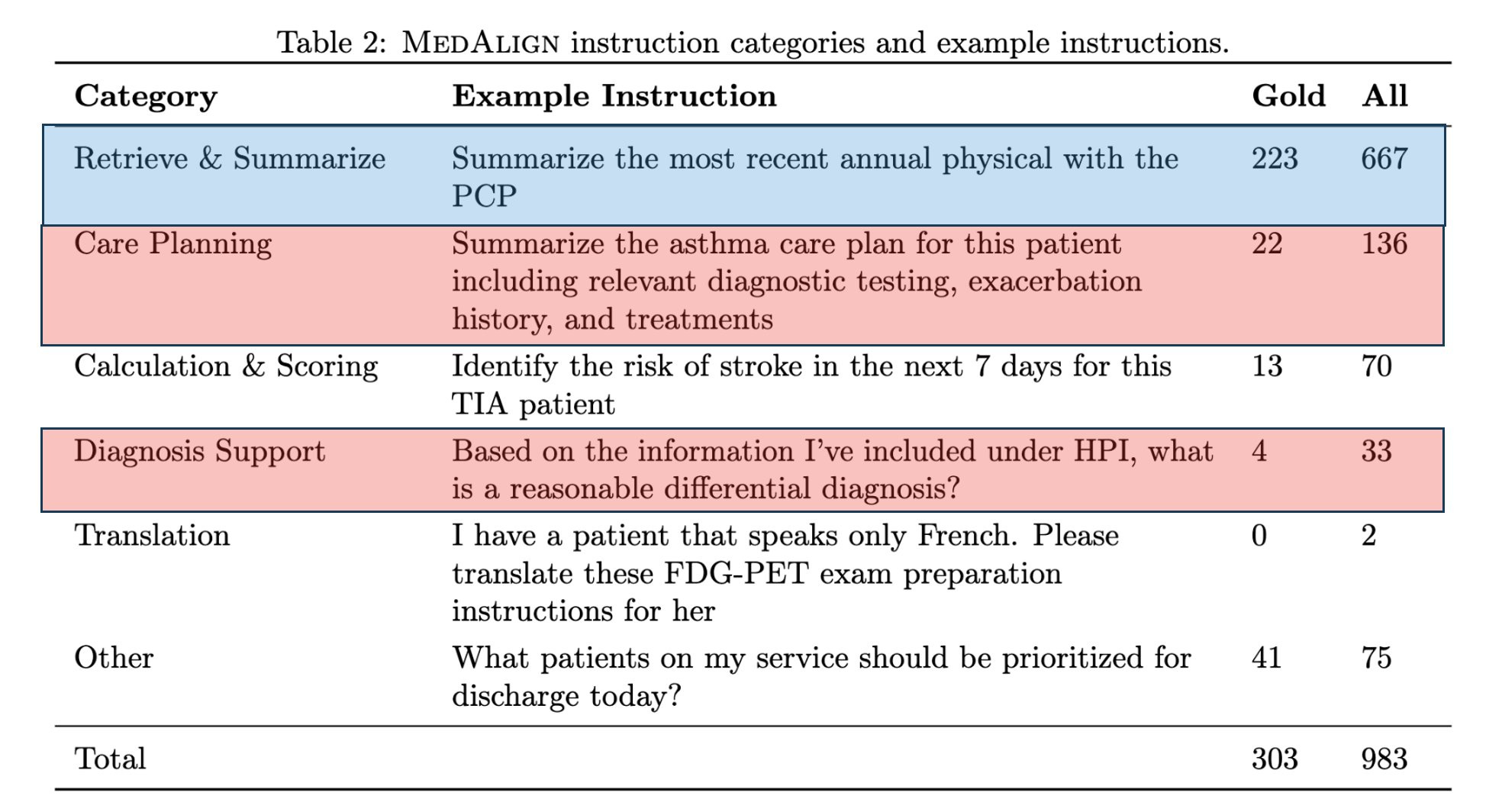
68% of tasks in EHR involve retrieving and summarizing data. Only 17% of the MedQA dataset includes these tasks.
3️⃣ There Are Consequences to Chasing Benchmarks, Not Real Use-Cases.

The open source community has developed several instruction-tuned large language models (LLMs). While these models show improved performance on MedQA-type tasks, they actually perform worse on MedAlign compared to their original non-medical base models, such as Llama-2, as highlighted in the MedAlign paper.
A recent study from Stanford found that widely used LLMs for medical assessments often can't substantiate their claims or references, highlighting the issue of “model hallucination”. The study notably concluded: “Our results are stark: Most models struggle to produce relevant sources. 4 out of 5 models hallucinate a significant proportion of sources by producing invalid URLs. This problem goes away with the retrieval augmented generation (RAG) model, which first performs a web search for relevant sources before producing a summary of its findings. However, even in the GPT-4 RAG model, we find that up to 30% of statements made are not supported by any sources provided, with nearly half of responses containing at least one unsupported statement. This finding is more exaggerated in the other four models, with as few as 10% of responses fully supported in Gemini Pro, Google's recently released LLM.”
We Are Many Years Away from AI Providing Medical Diagnosis and Treatment
To their credit, the Med-Gemini researchers acknowledge that AI models are far from ready for use in diagnostics and treatment in real-world settings.
Specifically, the authors note: “[S]uch [real-world] uses (particularly in safety-critical areas like diagnosis) would require considerable further research and development.”
The Silence of Mayo Clinic
It was announced in July 2023 that Google had been testing Med-Gemini’s predecessor, Med PaLM 2, at the Mayo Clinic.
Since then, both the Mayo Clinic and Google have been radio silent about the testing.
This is highly disturbing.
Interestingly, and somewhat bizarrely, at that same announcement, Google’s senior research director, Greg Corrado, said, “I don’t feel that this kind of technology is yet at a place where I would want it in my family’s healthcare journey.” However, he also added that the technology “takes the places in healthcare where AI can be beneficial and expands them by tenfold”. (Source: Engadget.)
Ouch.
I interpret this statement to mean that the development of AI in medicine is far ahead of practical real-world applications, and perhaps we need to slow down to ensure that AI benefits the ultimate customers: clinicians and patients.
Why Are LLMs Failing in Medicine?
I would be remiss not to mention an excellent source of information on healthcare on X, “Real Doc Speaks”.
In particular, I’m going to borrow his four reasons why Large Language Models (LLMs) are failing in real-world medical practice:
1️⃣ It is difficult to model biological behavior. There is significant variation in patients’ responses to treatments.
2️⃣ Errors in medicine can be catastrophic, and the tolerance for errors is very low in medicine.
3️⃣ It will take time and very large numbers to build out a credible database.
4️⃣ Physicians have the ultimate responsibility for the results of AI and will need time to review these results very carefully. This does not imply time savings nor a cure for physician burnout.
My Final Take
AI models need to be in the hands of doctors, not just researchers. Stop throwing more GPUs at your models. Make them usable.
Clinicians don’t care if an AI model has 86% accuracy, or 90% accuracy, or 91% accuracy, or even 100% accuracy on an irrelevant benchmark.
Don’t get me wrong: Google has been doing textbook training and fine-tuning of their LLMs. I mean everything, from training, embeddings, indexing, retrieval. Everything was done well. But let doctors use the models and share the results. Please.
While I’m super excited that on particular sets of medical benchmarks, Med-Gemini is now a state-of-the-art model, I’m concerned that Google jumped from Med PaLM 2 to Med-Gemini without properly testing it in a clinical setting. Google announced a big test of their previous medical LLM, MedPaLM 2, back in July 2023, and that was the last we’ve heard about that.
It’s very disconcerting. Google researchers have a goal to publish more papers to advance in their careers (hence, 71 co-authors). In the meantime, almost nothing has happened in advancing LLMs and other AI models in real-world clinical settings.
By the way, if Mayo Clinic had mediocre results with Med PaLM 2, that’s OK. Why wouldn't you share what happened with the medical and research communities, so we can all learn?
The AI revolution continues. Let’s just make sure we don’t leave doctors and patients behind.
👉👉👉👉👉 Hi! My name is Sergei Polevikov. In my newsletter ‘AI Health Uncut’, I combine my knowledge of AI models with my unique skills in analyzing the financial health of digital health companies. Why “Uncut”? Because I never sugarcoat or filter the hard truth. I don’t play games, I don’t work for anyone, and therefore, with your support, I produce the most original, the most unbiased, the most unapologetic research in AI, innovation, and healthcare. Thank you for your support of my work. You’re part of a vibrant community of healthcare AI enthusiasts! Your engagement matters. 🙏🙏🙏🙏🙏
That is upsetting about Mayo Clinic not sharing results. Also thank you for bringing up RAG systems vs LLMs. I’ve tried both for answering clinical questions and still can’t get over the reference hallucinations from ChatGPT3.5. SinjabAcademy’s Infinity RAG search tool for ophthalmology-related publications is meanwhile extremely helpful with a real reference list that is immediately accessible to verify claims and help guide decision making.
Excellent summary, thanks!