



It's Time for Doctors Who Publish to Learn Basic Math
Amid the reproducibility crisis, peer reviewers are the last frontier of quality medical research. And they're failing—badly.

Welcome to AI Health Uncut, a brutally honest newsletter on AI, innovation, and the state of the healthcare market. If you’d like to sign up to receive issues over email, you can do so here.
We’re in the middle of a massive reproducibility (replicability) crisis in healthcare. As a peer reviewer with a formal background in math, it’s heartbreaking to watch the sharp decline in research standards, especially in digital health—my area of expertise.
I’m not trying to beat a dead horse, but since Jenny Owens of the Cleveland Clinic invited me to speak about this on her excellent podcast (check out the full interview here), now feels like the right moment to spotlight the foundational role of math and statistics in medical research.
Honestly, I could go on about this for hours—as Jenny unfortunately found out. 😉
Since she asked me about that notorious JAMA paper, the one authored by 16 Stanford researchers, I’ll use it as a case study in what not to do. Not just in academic research, but in any line of work. This is a masterclass in failed due diligence.
So here’s what went down.

The notorious 2024 JAMA study by 16 Stanford researchers claimed that AI (specifically GPT-4) didn’t significantly enhance physicians’ performance in diagnostic reasoning—for a whopping total of 6 cases (yes, you read it right: n=6!). A secondary finding was that AI alone outperformed physicians by a substantial margin—again, based on the same tiny sample of 6 cases. Unfortunately, it was this secondary result that the media sensationalized and blew completely out of proportion.
The authors selected 50 physicians, each with an average of 3 years of experience, to solve 6 cases (though in reality it was more like 4 or 5, since the physicians were given limited time to work through them). They gave the same 6 cases to the AI (GPT-4).
Turned out, this study was a total flop, and I wrote about this here, here, and here. Yet it was eagerly picked up by prominent media outlets like The New York Times, CNN, and prominent researchers such as Eric Topol and Pranav Rajpurkar. And that’s the tragedy of academia today: in the era of the internet and social media, every piece of news, no matter how flawed or shallow, spreads like wildfire.
Here’s the kicker: 16 researchers from Stanford submitted a paper to JAMA riddled with elementary statistical errors that, if I’d seen them as a peer reviewer, would’ve led me to toss the manuscript into the trash without hesitation. Somehow, JAMA’s reviewers and editors decided to turn a blind eye. Then the media jumped in, playing broken telephone, broadcasting headlines like “AI beats human doctors in diagnostics,” when the study was actually limited to diagnostic reasoning. Worst of all, the authors went along with the hype.
It’s hands-down one of the worst studies I’ve encountered in my career. This study epitomizes precisely why we’re stuck neck-deep in a reproducibility (replicability) crisis in medical research, in particular in psychology and biomedicine.

How 16 smart people—not to mention JAMA peer reviewers and editors—missed a simple high-school-level error is beyond me. But it shows that the system of checks and balances is broken. Obviously, with so many papers being generated by AI these days, reviewers must be overwhelmed. But that’s absolutely not an excuse to not do your job.
In my own experience as a peer reviewer, the manuscripts I receive are always anonymous. Still, after a while, you start to recognize the authors by their writing style and, more importantly, by their references. So I wonder if some reviewers (and editors) were a little starstruck and failed to do their due diligence.
In any case, let me remind these 16 Stanford researchers—and the folks at JAMA who let this slide—of a few basic concepts: p-hacking and, more relevant here, effective sample size (ESS), or effective number of bets (ENB). The latter is a measure widely used in economics and finance. ESS is closely related to Principal Components Analysis (PCA)—which, I assume, all of us had to learn at some point, including these 16 Stanford PhDs and MDs.

I covered the reproducibility crisis, p-hacking, and other critical issues in medical research in detail in my recent publication, “Advancing AI in Healthcare: A Comprehensive Review of Best Practices.”
Let’s review the basics, in my own words, at a high school level. (No disrespect to high schoolers—many are definitely operating above this level.)
🤖 Reproducibility / Replicability Crisis
Back in the day, when medical science still respected academic standards, having your research reproduced by others was considered a badge of honor. Now? No one gives a sh*t. Data samples are manipulated. Data is tortured until it finally screams out the result the authors want. Unsurprisingly, most studies can’t be replicated anymore. It’s a tragedy for academia—and for the entire industry.
🤖 P-hacking
If you’re running an empirical study, you usually want your p-value to be statistically significant—typically below 0.05. There are honest ways to get there, and dishonest ones. P-hacking is the latter. One basic example: run 100 different subsamples until one gives you the result you want, then publish only that one. That’s not science. That’s cheating.
🤖 Effective Sample Size (ESS) / Effective Number of Bets (ENB)
In investing, buying the S&P 500 isn’t 500 separate bets. It’s one effective bet—because when sh*t hits the fan, like it has in the last few days, most stocks moves together. (Same goes for venture capital and private equity—don’t kid yourself just because your VC fund’s NAV hasn’t dropped in your account. Just wait for your next quarterly report. 😉 The days of private-public diversification are long gone.) Same logic applies in medical research. If your variables are correlated, you don’t have as many independent data points as you think. This is common sense. Or at least, it should be.
So what happened in this particular JAMA study?
The unfortunate thing—i.e. sh*t—happened. The authors made an error, doubled down on their results (which lacked statistical significance) in interviews with the press, and never really admitted the mistake. The only time they acknowledged something was in a comment on one of my posts, where they said that “AI outperforming doctors” was a “secondary result.”
Well, that’s not even the point. But by the way—why didn’t you mention that in your interview with CNN and the rest of the media?
It’s shameful and disgusting, in my opinion. We should be doing a hell of a lot better than that as an industry.
As I said, even after being confronted, the authors sort of backed off the “AI outperformed doctors” claim. But they kept pushing the idea that the sample size was 50—because that’s the number of physicians (well, PAs in this case) they used. And then it hit me: Oh my God. These folks don’t understand basic statistics.

Look, I’m not claiming to be a genius. But I’m not the one submitting a paper to one of the most respected journals in medicine with a result—“AI outperforms doctors in diagnosis”—that got blasted across every major media outlet.
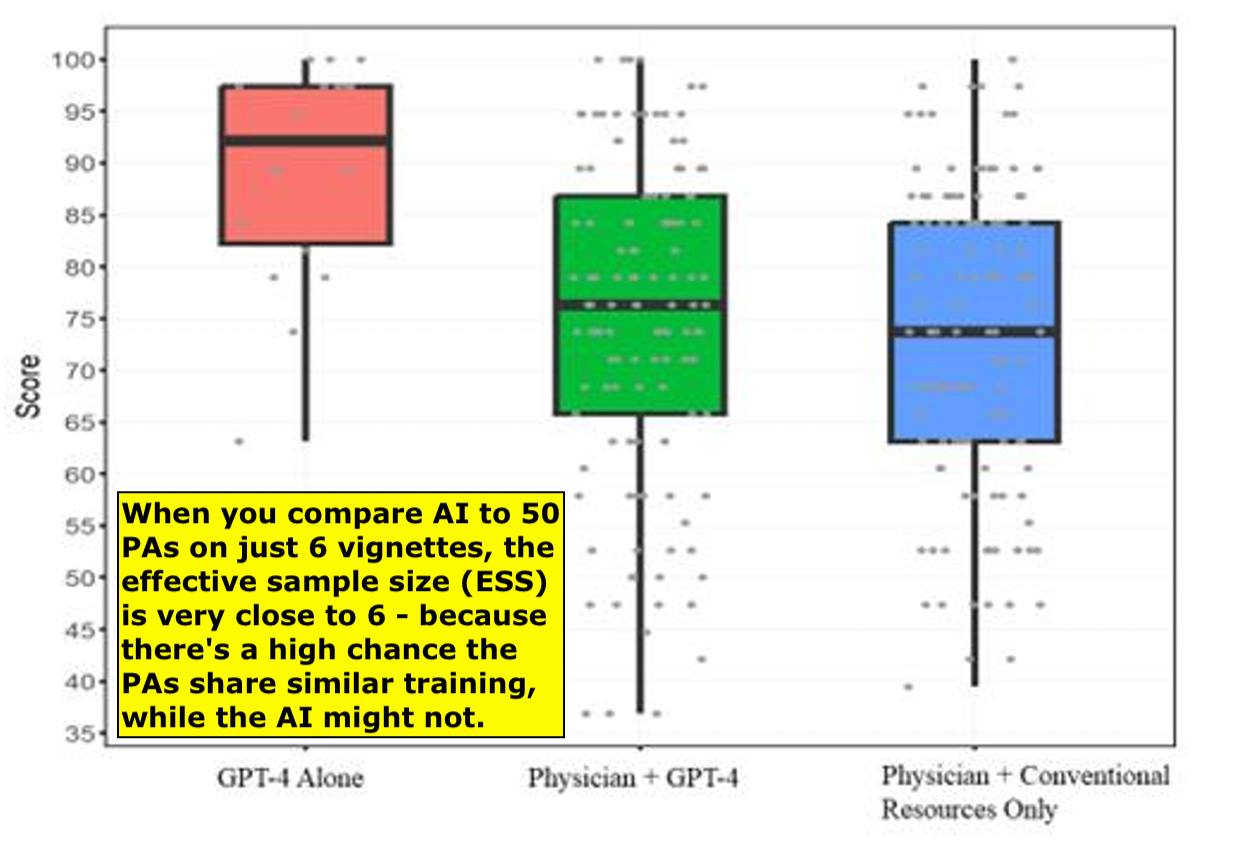
Here’s my argument. The effective sample size (ESS)—the one that actually matters for statistical significance—was basically 6 in this study.
Why? Let me break it down. Let’s push it to the limit, like we often do in math. Suppose you only have one medical case. Just one. (Which, by the way, isn’t far off from 6 😉). Now, imagine you have one million physicians reviewing that one case. Assume they all had similar training and residency backgrounds.
In this (yes, simplified) scenario, it’s easy to see the issue. If a significant number of physicians miss that one case—and AI nails it—well, guess who looks like the genius? AI. And honestly, that’s not far-fetched. Most of the physicians in the study didn’t have much experience. And given the recent Llama 4 “leaky benchmark” findings, it’s not out of the question that the AI had seen that case—or something close to it—before.
So yes, AI could score close to 100%. And humans might do poorly. But that’s not evidence of AI superiority in a robust sense. It just shows that AI might be better on that specific small sample, or that specific narrow task. That’s not what the authors proved with any statistical confidence.
It’s really that simple. You don’t even need to know what p-hacking is to see what’s wrong here. It’s just common sense.
Let’s do better. Let’s learn the math. Let’s understand what effective sample size is—and why it matters.
If you want to learn more about this topic, please listen to my full interview with Jenny Owens. In addition to the critical issues outlined, here are some other things we discussed:
Critique of the JAMA LLM Study Claiming AI Outperformed Human Doctors:
Methodological flaws include p-hacking and misinterpretation of statistical significance.
Effective sample size (ESS) not properly accounted for.
Structured vignettes do not reflect real-world clinical complexity.
Recommended Study Designs:
Hybrid design with physicians diagnosing cases with and without LLMs in randomized order.
Cluster-randomized trials in clinical settings (e.g. randomizing hospital units or shifts).
Blinding outcome assessors and, when possible, physicians to reduce bias.
Key Gaps Between Theory and Practice:
Real-world data is messy and incomplete, unlike structured vignettes.
LLMs regurgitate knowledge but struggle with real-time synthesis of new info.
Physicians are legally liable for AI-assisted errors — a major adoption barrier.
AI Hype and Public Perception:
Media headlines often overstate AI performance, misleading patients and policymakers.
Sensational narratives distract from healthcare priorities and realistic assessments.
How to Detect AI Hype:
Look for peer-reviewed validation in real clinical settings.
Be skeptical of “fully automated” claims — best practice is human-in-the-loop.
Regulators like the FDA emphasize local validation and ongoing monitoring.
Alternative AI Use Cases:
Automation doesn’t always require AI — sometimes simpler tools suffice.
Real AI value lies in augmenting care, not replacing clinicians.
Tasks like triage, administrative streamlining, and early screening offer more promise.
Separation of Labor:
Drs. Eric Topol and Pranav Rajpurkar argue that AI should handle routine, low-risk tasks (e.g. normal X-rays, simple mammograms). Human doctors should focus on complex, nuanced cases.
I argue that AI could excel at complex, rare cases because it’s already proven to handle nonlinear tasks incredibly well.
Separation of labor could ease workforce shortages and improve care, especially in underserved areas.
“Doctors Go to Jail. Engineers Don’t.”:
Legal liability remains a fundamental hurdle to AI deployment in clinical settings.
I’m about to add more haters to my already long list. But here it goes.
If you’ve already got an army of authors (16, seriously?), make sure at least one of them knows statistics, isn’t junior, and has the guts to say to the group, “This is crap. We shouldn’t submit this to any journal. We can do better.” In this case, all 16 should’ve caught a basic statistical error. But either they didn’t know, or they chose to ignore it, hoping this subpar research would slip through. And it sure did!
We have to do better in medical research. All of us — researchers, peer reviewers, editors, the media. This isn’t politics. There’s no place for lies or lazy shortcuts in research, especially not in medical research, where real people’s health and lives are on the line.
Like what you’re reading in this newsletter? Want more in-depth investigations and research like this?
I’m committed to staying independent and unbiased—no sponsors, no advertisers. But that also means I’m a one-man operation with limited resources, and investigations like this take a tremendous amount of effort.
Consider becoming a Founding Member of AI Health Uncut and join the elite ranks of those already supporting me at the highest level of membership. As a Founding Member, you’re not just backing this work—you’re also helping cover access fees for those who can’t afford it, such as students and the unemployed.
You’ll be making a real impact, helping me continue to challenge the system and push for better outcomes in healthcare through AI, technology, policy, and beyond.
Thank you!
👉👉👉👉👉 Hi! My name is Sergei Polevikov. I’m an AI researcher and a healthcare AI startup founder. In my newsletter ‘AI Health Uncut,’ I combine my knowledge of AI models with my unique skills in analyzing the financial health of digital health companies. Why “Uncut”? Because I never sugarcoat or filter the hard truth. I don’t play games, I don’t work for anyone, and therefore, with your support, I produce the most original, the most unbiased, the most unapologetic research in AI, innovation, and healthcare. Thank you for your support of my work. You’re part of a vibrant community of healthcare AI enthusiasts! Your engagement matters. 🙏🙏🙏🙏🙏
Medical publications have devolved into publishing articles that can generate buzz in the media. This has become the new Impact Factor rendering prestige to these medical journals. They are no different than websites that produce clickbait headlines.