


Welcome to AI Health Uncut, a brutally honest newsletter on AI, innovation, and the state of the healthcare market. If you’d like to sign up to receive issues over email, you can do so here.
I’m honored that this article will also appear in the next edition of Artificial Intelligence Made Simple, a renowned Substack publication that covers everything you need to know about hot topics in AI and the intricacies of machine learning models, written by the respected expert and star author, Devansh. I encourage all of you to visit and subscribe to Artificial Intelligence Made Simple.
Over the past few days, I’ve been exploring the diagnostic capabilities of the new o1 ‘Strawberry’ model.
My verdict: even the best large language models (LLMs) we have are not ready for prime time in healthcare.
The o1 ‘Strawberry’ model hasn’t just inherited the habit of confidently lying from its predecessor, the 4o model, when it misdiagnoses. Unlike the 4o model, it now rationalizes these lies. Whether you call them hallucinations or use some other data science jargon, in the context of clinical decision-making, this is simply wrong information. With the help of the Strawberry 🍓, these errors are now perfectly rationalized. When lives are at stake, this is not just a problem — it’s downright dangerous.
I’m not surprised, to be honest. At yesterday’s Senate hearing before the Subcommittee on Privacy, Technology, and the Law, OpenAI whistleblower William Saunders testified that the company has “repeatedly prioritized speed of deployment over rigor.” While Saunders made this statement specifically regarding the development of Artificial General Intelligence (AGI), his testimony hinted at a broader culture within OpenAI, especially among its executives. (Source: C-SPAN.)
Since its inception, OpenAI has embraced a ‘Lean Startup’ culture—quickly developing an MVP (Minimum Viable Product), launching it into the market, and hoping something “sticks.” The benefit of this approach is clear: it’s cost-effective, saves time, and provides invaluable feedback from real customers. However, the downside is just as significant. By releasing a ‘half-baked’ product, you risk disappointing a large group of customers—many of whom may never come back.
This might be a viable strategy for a fledgling fintech startup, but it’s reckless and dangerous for a company like OpenAI, especially when they now promote applications in critical areas like medical diagnostics.
But let’s start from the beginning…
Here’s a sneak peek at the roadmap for the article:
1. OpenAI o1 ‘Strawberry’ Launch 🍓
2. OpenAI Claims Its New o1 ‘Strawberry’ Model Can Handle Medical Diagnosis. Not a Chance! 🍓
3. The Sweetness of the Strawberry – Some People Love It 🍓
3.1. AgentClinic-MedQA Claims Strawberry is the Top Choice for Medical Diagnostics
3.2. AgentClinic-MedQA Faces a Benchmark Issue
3.3. Healthcare Applications of o1 ‘Strawberry’ by Oscar Health
4. The Sour Side of the Strawberry – OpenAI Hallucinates in Its Own Cherry-Picked Use Case 🍓
5. Clinicians to OpenAI: Show Us the Probabilities or Stop Lying to Us!
6. Conclusion
1. OpenAI o1 ‘Strawberry’ Launch 🍓
On Thursday, September 12, 2024, OpenAI introduced o1, describing it as “a new large language model trained with reinforcement learning to perform complex reasoning. o1 thinks before it answers—it can produce a long internal chain of thought before responding to the user.” According to the announcement, based on common industry benchmarks, o1 appears to surpass GPT-4o (hereafter referred to as 4o) in accuracy and, as OpenAI suggests, in reducing hallucinations. (Source: OpenAI o1 announcement.)
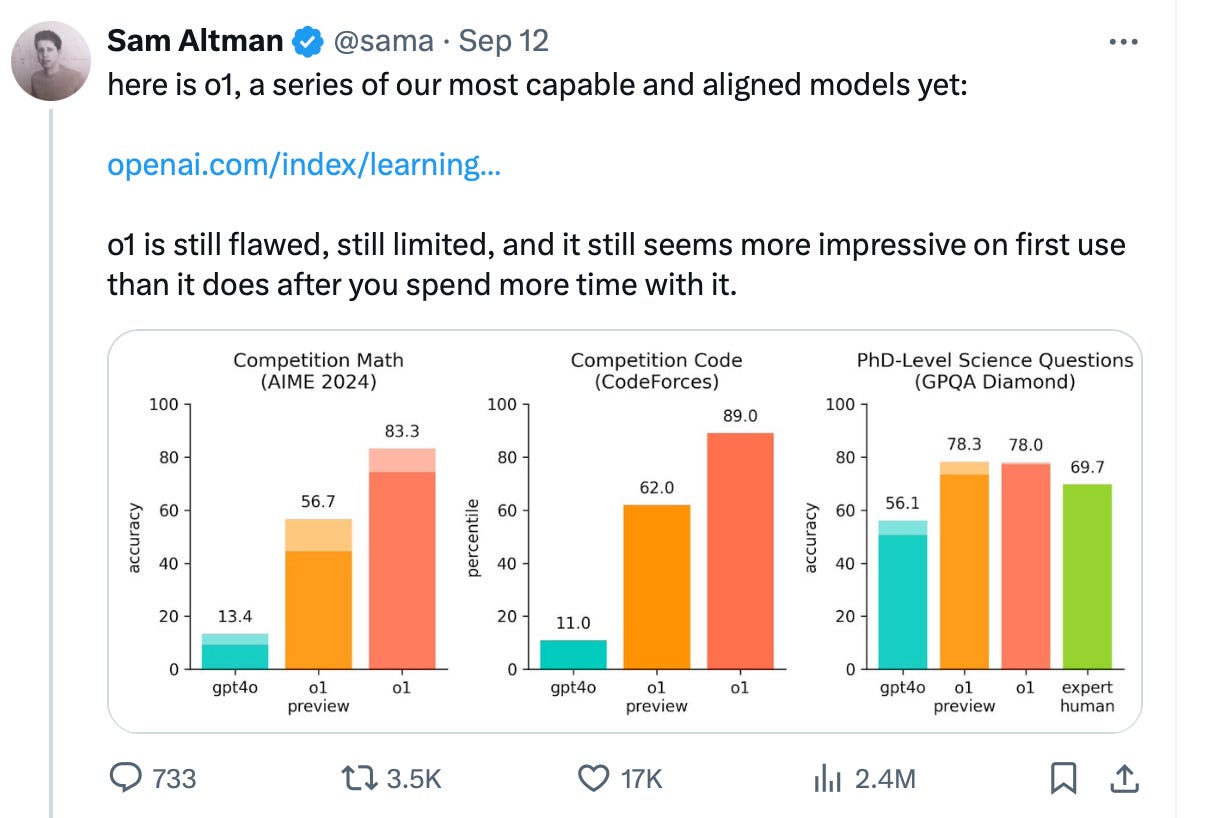
Sam Altman, CEO of OpenAI, called o1 “our most capable and aligned model yet,” but admitted that o1 is “still flawed, still limited, and still seems more impressive at first use than after spending more time with it.” (Source: Sam Altman on X.)”
2. OpenAI Claims Its New o1 ‘Strawberry’ Model Can Handle Medical Diagnosis. Not a Chance! 🍓
What’s fascinating is that, for the first time ever, a foundational model—without any fine-tuning on medical data—is offering a medical diagnosis use case in its new release!
If you’ve been following my research, you might remember what I predicted just five weeks ago: “The next version of foundational models is so good they outperform the current generation of models fine-tuned on specific medical datasets. It’s crazy. 🤯” And right on cue, OpenAI came through. 😎
But, there’s a teeny tiny hiccup no one seems to be talking about: the medical diagnosis use cases OpenAI cherry-picked had hallucinations—big ones! 🤯 I’ll dive into those later. First, let’s break down how they’re claiming the o1 model is useful in medicine.
And before we go any further, let's take a look at the medical industry’s reaction to the o1 ‘Strawberry’ announcement.
3. The Sweetness of the Strawberry – Some People Love It 🍓
3.1. AgentClinic-MedQA Claims ‘Strawberry’ is the Top Choice for Medical Diagnostics
As with any new AI release, the hype started instantly.
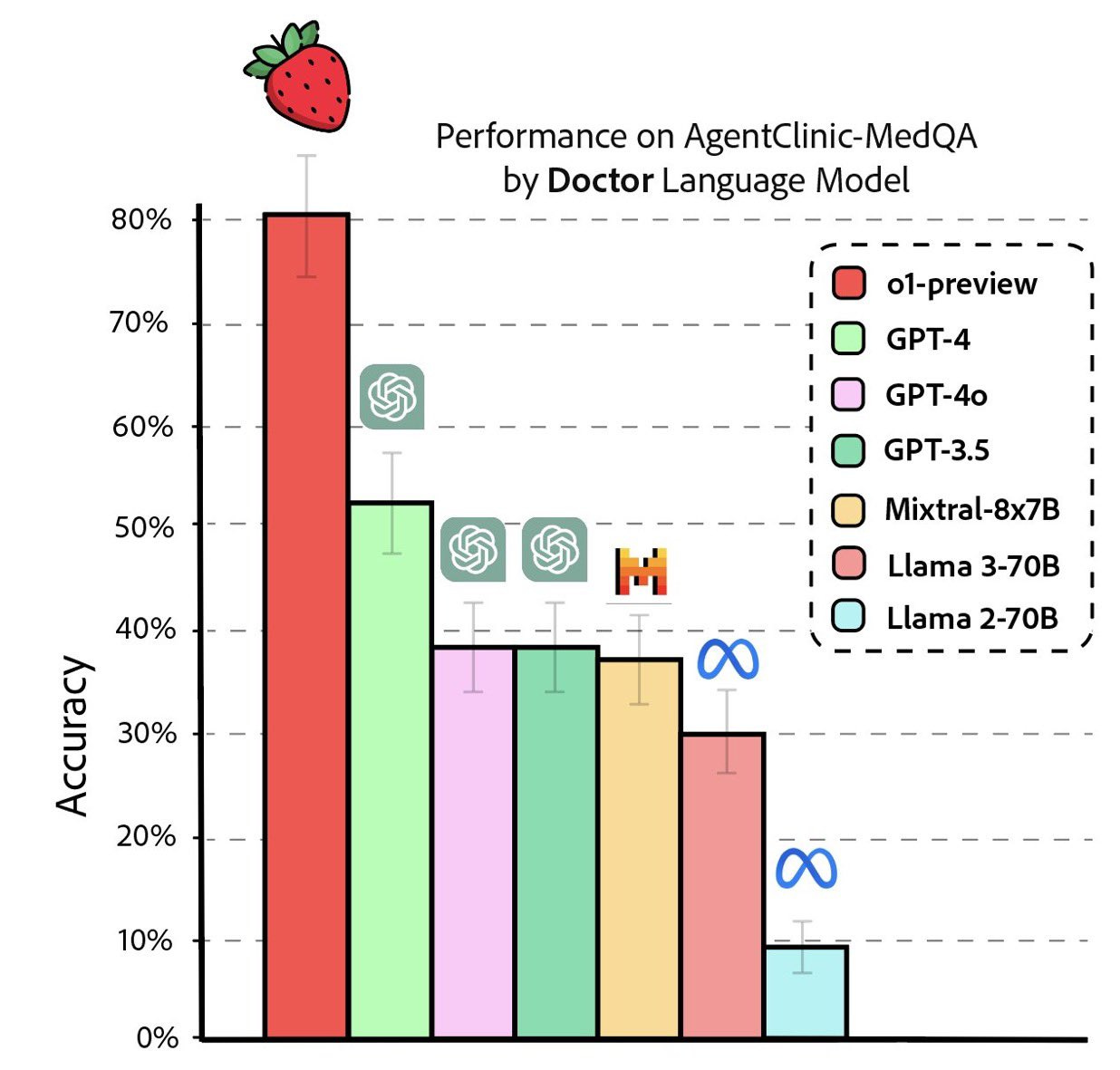
Researchers from Stanford University, Johns Hopkins University, and Hospital Israelita Albert Einstein wasted no time testing the brand new ‘AgentClinic’ specialized medical dataset benchmark. It wasn’t long before this image went viral. (Sources: AgentClinic paper, AgentClinic on Github.io.)
Over on Reddit, the crowd was quick to proclaim, “OpenAI’s o1-preview accurately diagnoses diseases in seconds and matches human specialists in precision. Only surgeries and emergency care are safe from the risk of AI replacement.” (Source: Reddit.)
“...the massive performance leap of OpenAI’s o1-preview model, also known as the ‘Strawberry’ model, which was released as a preview yesterday. The model performs exceptionally well on a specialized medical dataset (AgentClinic-MedQA), greatly outperforming GPT-4o. The rapid advancements in AI’s ability to process complex medical information, deliver accurate diagnoses, provide medical advice, and recommend treatments will only accelerate.”
“…medicine is becoming a less appealing career path for the next generation of doctors--unless they specialize in intervention-focused areas (such as surgery, emergency medicine, and other interventional specialties), though these, too, may eventually be overtaken by robotic systems...maybe within a decade or so.”
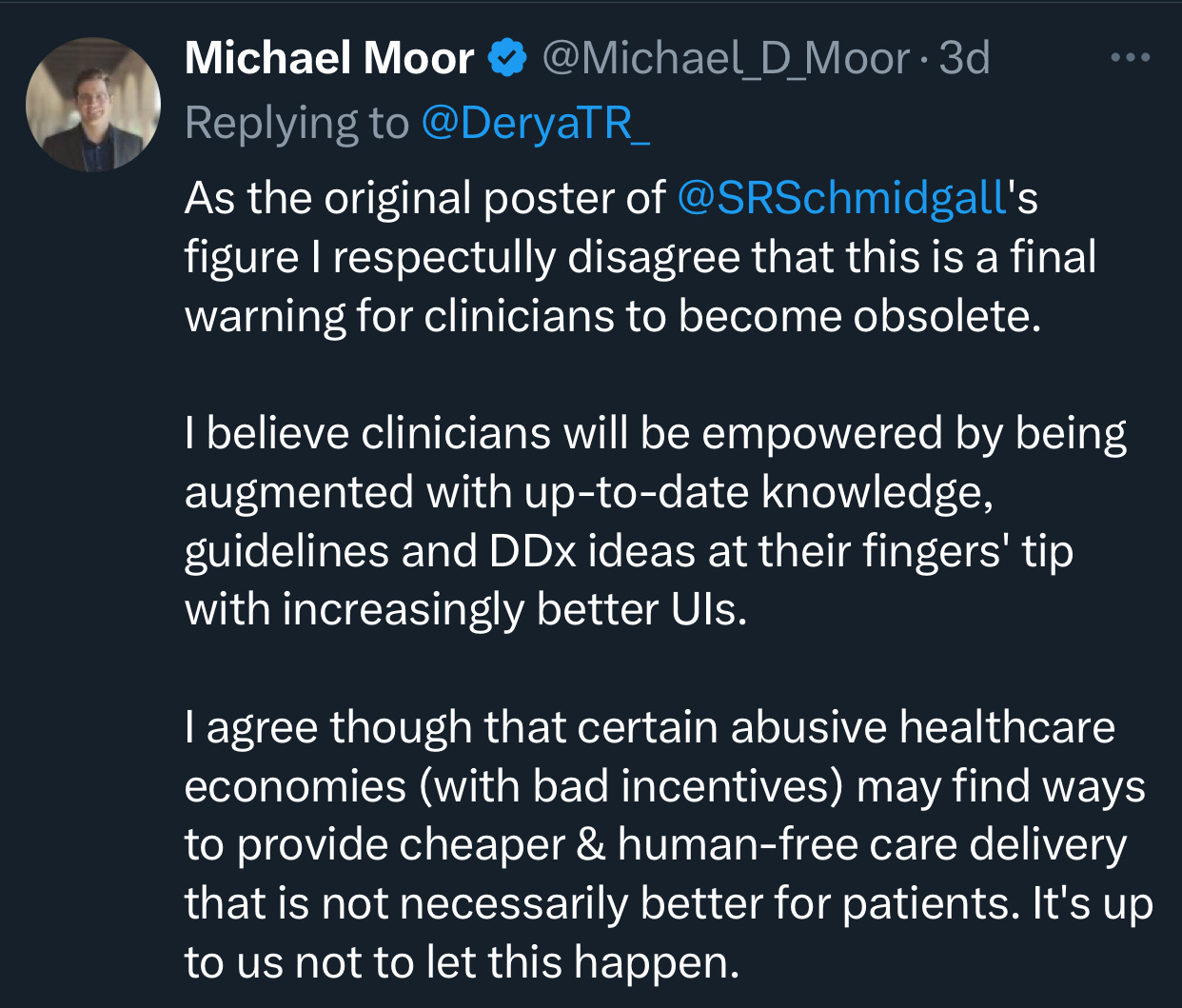
Derya Unutmaz, MD chimed in on X: “This is the final warning for those considering careers as physicians: AI is becoming so advanced that the demand for human doctors will significantly decrease, especially in roles involving standard diagnostics and routine treatments, which will be increasingly replaced by AI.”
People often spout wild sh*t on social media just for the clicks.
3.2. AgentClinic-MedQA Faces a Benchmark Issue
The reality is, we’re still decades away from AI fully replacing doctors. As I pointed out in my critique of Google’s Med-Gemini model, benchmarks for AI in medicine are riddled with major flaws. Data scientists, myself included, are mesmerized by the race for what I call “theoretical” accuracy with each new LLM. But when it comes to “practical” accuracy, we’ve seen almost no real progress.
Using non-practical benchmarks, along with other statistical issues, presents a serious challenge we must overcome to achieve real progress.
We, data scientists, put too much faith in benchmarks.
But the truth is:
“Benchmarks are gameable and aren’t representative of the complexities found in real-world applications.” —Logan Thornloe
(Source: “How to Use Benchmarks to Build Successful Machine Learning Systems” by Logan Thornloe.)
This issue of faulty benchmarks is especially critical in healthcare.
In my previous research, I’ve highlighted major issues with biomedical benchmarks like MedQA (including USMLE) and MedMCQA, particularly overfitting and data contamination.
However, there are also additional issues with medical benchmarks. I’ll highlight a few compelling points raised against benchmarking to MedQA by Jason Alan Fries, one of the co-authors of the MedAlign paper, shared on X. Similarly, Cyril Zakka, MD, has pointed out concerns about the AgentClinic dataset, also on X:
1️⃣ MedQA doesn’t reflect realistic EHR data.
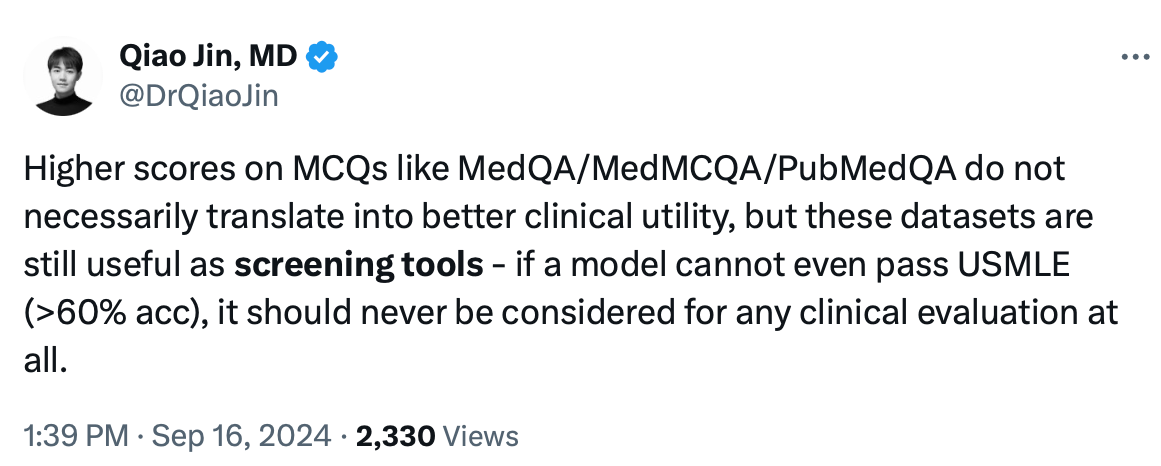
2️⃣ Clinicians are looking for something practical that works for retrieving and summarizing data. MedQA is misaligned with those needs.
3️⃣ There are consequences to chasing benchmarks, not real use-cases.
4️⃣ The AgentClinic dataset is based on an online dataset. (Source: Cyril Zakka, MD on X.)
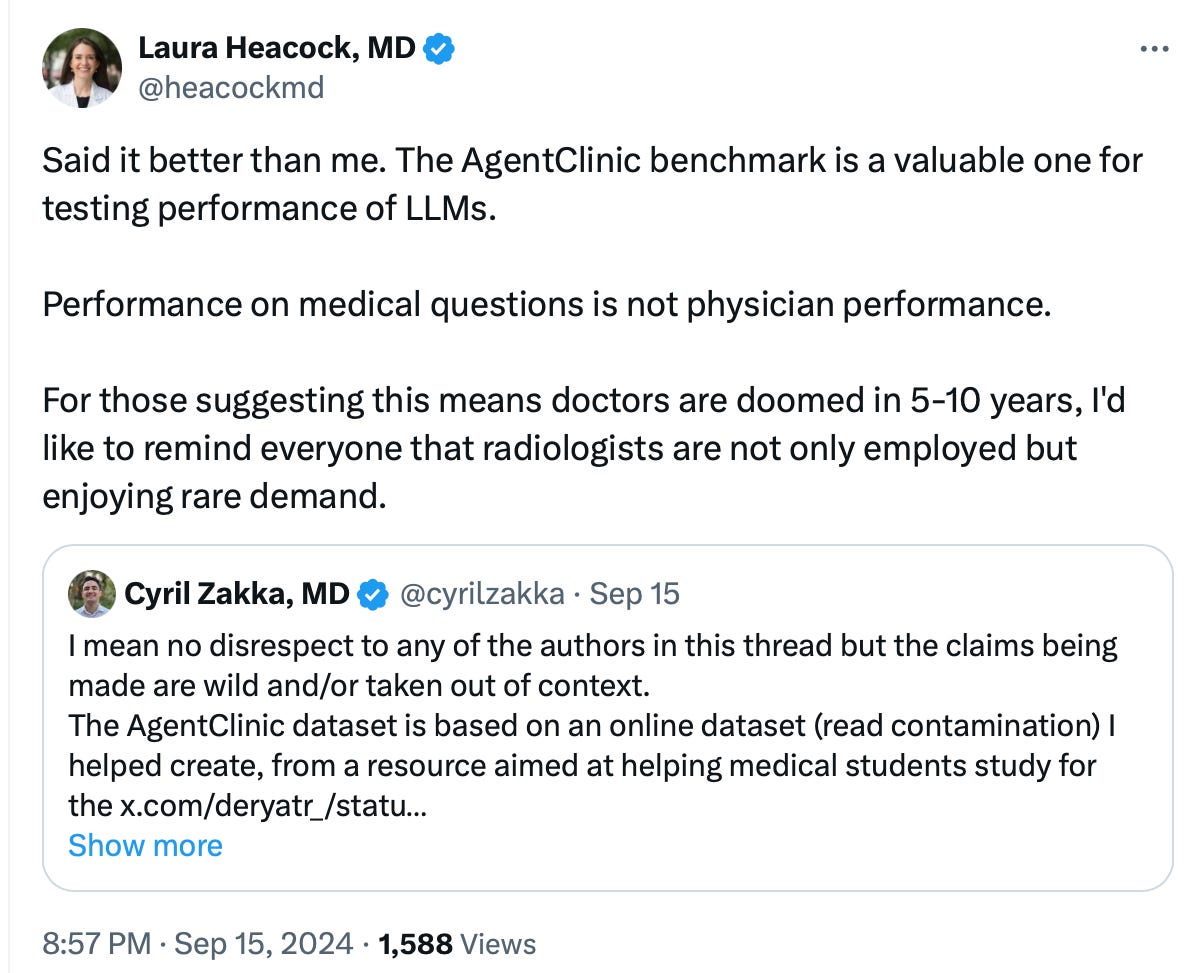
So no, o1 ain’t Skynet. It’s not going to kill clinicians’ jobs.
Note: 1. The MedQA benchmark is a dataset and evaluation framework designed to test the capabilities of AI models, particularly large language models (LLMs), in medical question answering. It typically contains multiple-choice questions from medical licensing exams, such as the United States Medical Licensing Examination (USMLE), and is used to assess how well these models can understand and answer complex medical questions, often requiring deep domain knowledge. 2. MedMCQA (Medical Multiple-Choice Question Answering) is a large-scale, multiple-choice question dataset designed to evaluate and improve the performance of AI models, particularly large language models (LLMs), in medical question-answering tasks. 3. MCQ stands for Multiple Choice Questions.
3.3. Healthcare Applications of o1 ‘Strawberry’ by Oscar Health
I’d be remiss not to mention the exceptional overview of o1 ‘Strawberry’ use cases by Oscar Health and its co-founder and CTO, Mario Schlosser. (Sources: Oscar Health, Mario Schlosser on X.)

1️⃣ Claim Pricing/Adjudication
2️⃣ Navigating Clinical Guidelines
3️⃣ Fraud, Waste, and Abuse (FWA)
4️⃣ Medical Records / Clinical Reviews
5️⃣ Automating Providers’ Administrative Tasks
It’s definitely worth reading for anyone curious about how the o1 model has mostly outperformed the 4o model and its implications for healthcare applications. Here’s the link again: Oscar Health’s early observations on OpenAI o1-preview.
4. The Sour Side of the Strawberry – OpenAI Hallucinates in Its Own Cherry-Picked Use Case 🍓
Now, let’s revisit OpenAI’s botched attempt at a medical diagnosis use case. In its September 12 o1 model announcement, OpenAI cherry-picked the following example as a showcase:
Question for o1-review: Make a diagnosis based on the following report:
Phenotypes:
Intellectual disability
Global developmental delay
Macrodontia
Triangular face
Thick eyebrow
Abnormality of the hand
Short stature
Motor delay
Delayed speech and language
Feeding difficulties
Low anterior hairline
Strabismus
Anteverted nares
Bulbous nose
Excluded phenotypes:
Atrioventricular canal defect
Patent foramen ovale
Ventricular septal defect
Pulmonic stenosis
Bicuspid aortic valve
Mixed hearing impairment
Microcephaly
Synophrys
Response of the o1-preview model during its launch:
Based on the provided phenotypic features and the exclusion of certain conditions, the most fitting diagnosis is KBG syndrome.
Rationale:
Included Phenotypes Matching KBG Syndrome:
Intellectual Disability and Global Developmental Delay: KBG syndrome is characterized by mild to moderate intellectual disability and developmental delays in both motor and speech domains.
Macrodontia: One of the hallmark features of KBG syndrome is macrodontia, specifically of the upper central incisors.
Triangular Face: Individuals with KBG often have a triangular-shaped face due to a broad forehead and a pointed chin.
Thick Eyebrows: Bushy or thick eyebrows are a common facial feature.
Abnormality of the Hand: Skeletal anomalies, including brachydactyly (short fingers) and clinodactyly (curved fingers), are frequently observed.
Short Stature: Many individuals exhibit growth delays resulting in short stature.
Motor Delay and Delayed Speech and Language: Developmental delays are common, affecting both motor skills and speech.
Feeding Difficulties: Infants may have difficulties with feeding due to hypotonia or other oral-motor issues.
Low Anterior Hairline: A low hairline at the front of the head is a recognized feature.
Strabismus: Eye anomalies, including strabismus (crossed eyes), are reported.
Anteverted Nares and Bulbous Nose: Facial features often include a bulbous nasal tip and anteverted (upturned) nostrils.
Excluded Phenotypes Aligning with KBG Syndrome:
Cardiac Anomalies: While some individuals with KBG syndrome may have heart defects, they are not a consistent feature, and the specific heart anomalies listed (e.g., atrioventricular canal defect, ventricular septal defect) are not commonly associated with KBG.
Hearing Impairment and Microcephaly: These are not primary features of KBG syndrome, and their exclusion aligns with the diagnosis.
Synophrys: Unibrow or synophrys is not typically associated with KBG syndrome; in contrast, thick but separate eyebrows are characteristic.
Conclusion:
Given the combination of characteristic facial features (triangular face, thick eyebrows, bulbous nose, anteverted nares, low anterior hairline), macrodontia, skeletal anomalies of the hands, short stature, developmental delays, and the absence of excluded phenotypes, KBG syndrome is the most appropriate diagnosis.
References:
KBG Syndrome Overview: KBG syndrome is a genetic disorder caused by mutations in the ANKRD11 gene. It is inherited in an autosomal dominant pattern.
Clinical Features: The syndrome is characterized by macrodontia of the upper central incisors, distinctive facial features, short stature, skeletal anomalies, and developmental delays.
Recommendation:
Genetic Testing: Confirmation of the diagnosis can be achieved through molecular genetic testing for mutations in the ANKRD11 gene.
Multidisciplinary Management: Patients benefit from a team approach, including pediatricians, geneticists, dentists, speech therapists, and occupational therapists, to address the various clinical manifestations.
Diagnosis: KBG Syndrome
Then they compare it to the response from the 4o model, where the answer was “Cornelia de Lange Syndrome is the most consistent diagnosis based on the provided phenotypic report,” touting how much better the model is working now. Of course, they ensured the disease was thoroughly described with an abundance of symptoms—which, naturally, is far from the reality of clinical practice. In real life, patients often report just a couple of symptoms, leaving it to the physician to piece together the rest. But that’s a minor detail when compared to the bigger issue of continued hallucinations.
The results sound amazing, right? Why not make o1 the standard of care? Not only does it seem to provide a correct diagnosis, it even gives an explanation that feels perfect about how it arrived there.
But I guess what OpenAI didn’t count on was someone actually fact-checking their claims.
So, I asked o1-preview the exact same question from OpenAI’s announcement use case. Here’s the answer I got on my very first try.
Response of the o1-preview model to the same question on my first attempt:
Diagnosis: Kabuki Syndrome
Chain of Thought:
To arrive at the most probable diagnosis, we’ll systematically analyze the provided phenotypes and consider genetic syndromes that align with these features while also ensuring that excluded phenotypes do not conflict with our conclusion.
Key Phenotypes:
Intellectual disability
Global developmental delay
Macrodontia (large teeth)
Triangular face
Thick eyebrows
Abnormality of the hand
Short stature
Motor delay
Delayed speech and language
Feeding difficulties
Low anterior hairline
Strabismus (crossed eyes)
Anteverted nares (upturned nostrils)
Bulbous nose
Excluded Phenotypes:
Congenital heart defects: Atrioventricular canal defect, Patent foramen ovale, Ventricular septal defect, Pulmonic stenosis, Bicuspid aortic valve
Mixed hearing impairment
Microcephaly (small head size)
Synophrys (unibrow)
Candidate Syndromes:
Cornelia de Lange Syndrome: Features synophrys and microcephaly (both excluded).
Noonan Syndrome: Often includes pulmonic stenosis (excluded) and doesn’t typically present with macrodontia.
Williams Syndrome: Characterized by elfin facies and cardiac defects (supravalvular aortic stenosis not mentioned).
Rubinstein-Taybi Syndrome: Features broad thumbs and toes (not mentioned), and while it includes intellectual disability and facial features, macrodontia is less common.
Kabuki Syndrome: Aligns closely with the given phenotypes and lacks the excluded features.
Matching Kabuki Syndrome Features:
Facial Features:
Long palpebral fissures
Arched and broad eyebrows (thick eyebrows)
Eversion of the lateral third of the lower eyelid
Depressed nasal tip and bulbous nose
Prominent ears
Low anterior hairline
Triangular face
Anteverted nares
Dental Anomalies:
Macrodontia
Growth and Development:
Short stature
Intellectual disability
Global developmental delay
Motor delay
Delayed speech and language development
Feeding difficulties
Musculoskeletal Anomalies:
Abnormalities of the hands (e.g., brachydactyly, clinodactyly)
Ophthalmologic Features:
Strabismus
Consistency with Excluded Phenotypes:
Kabuki Syndrome can have congenital heart defects, but not all patients exhibit them, and the specific excluded heart defects are not defining features.
Microcephaly and synophrys are not characteristic of Kabuki Syndrome.
Hearing impairment can occur but is not universal and is often conductive rather than mixed.
Conclusion:
Given the strong correlation between the patient’s phenotypes and the characteristic features of Kabuki Syndrome, along with the absence of conflicting excluded phenotypes, Kabuki Syndrome is the most probable diagnosis.
References:
Kabuki Syndrome Overview: National Organization for Rare Disorders (NORD)
Clinical Features of Kabuki Syndrome: Genetics Home Reference
Final Diagnosis: Kabuki Syndrome
Wait, what? It’s a perfectly rational explanation—but for a completely different diagnosis!
KBG Syndrome and Kabuki Syndrome are both genetic disorders, but they are definitely not the same.
If you run o1-preview hundreds of times with that same question, you’ll get a mix of KBG Syndrome diagnoses, Kabuki Syndrome diagnoses, and several others. And each time, the model insists that its diagnosis is the best fit for the same set of symptoms!
By the way, if you torture the 4o model long enough, you end up with a similar list of diagnoses as o1. The only real difference is the shape of the distribution (i.e., the probability values).
OpenAI’s cherry-picking of answers for their medical diagnosis use case was completely dishonest.
And once you start digging, you find hallucinations everywhere in the o1 ‘Strawberry’ model:
🔺 o1 confuses Werner Syndrome with Hutchinson-Gilford Progeria Syndrome (HGPS).
🔺 o1 confuses Chronic Obstructive Pulmonary Disease (COPD) with Congenital Central Hypoventilation Syndrome (CCHS).
🔺 o1 confuses Stiff Person Syndrome (SPS) with Parkinson’s disease.
🔺 o1 confuses Stevens-Johnson Syndrome (SJS) with Paraneoplastic Pemphigus.
🔺 o1 confuses Scleroderma (Systemic Sclerosis) with Harlequin Ichthyosis.
5. Clinicians to OpenAI: Show Us the Probabilities or Stop Lying to Us!
What should OpenAI and other AI developers do to improve healthcare?
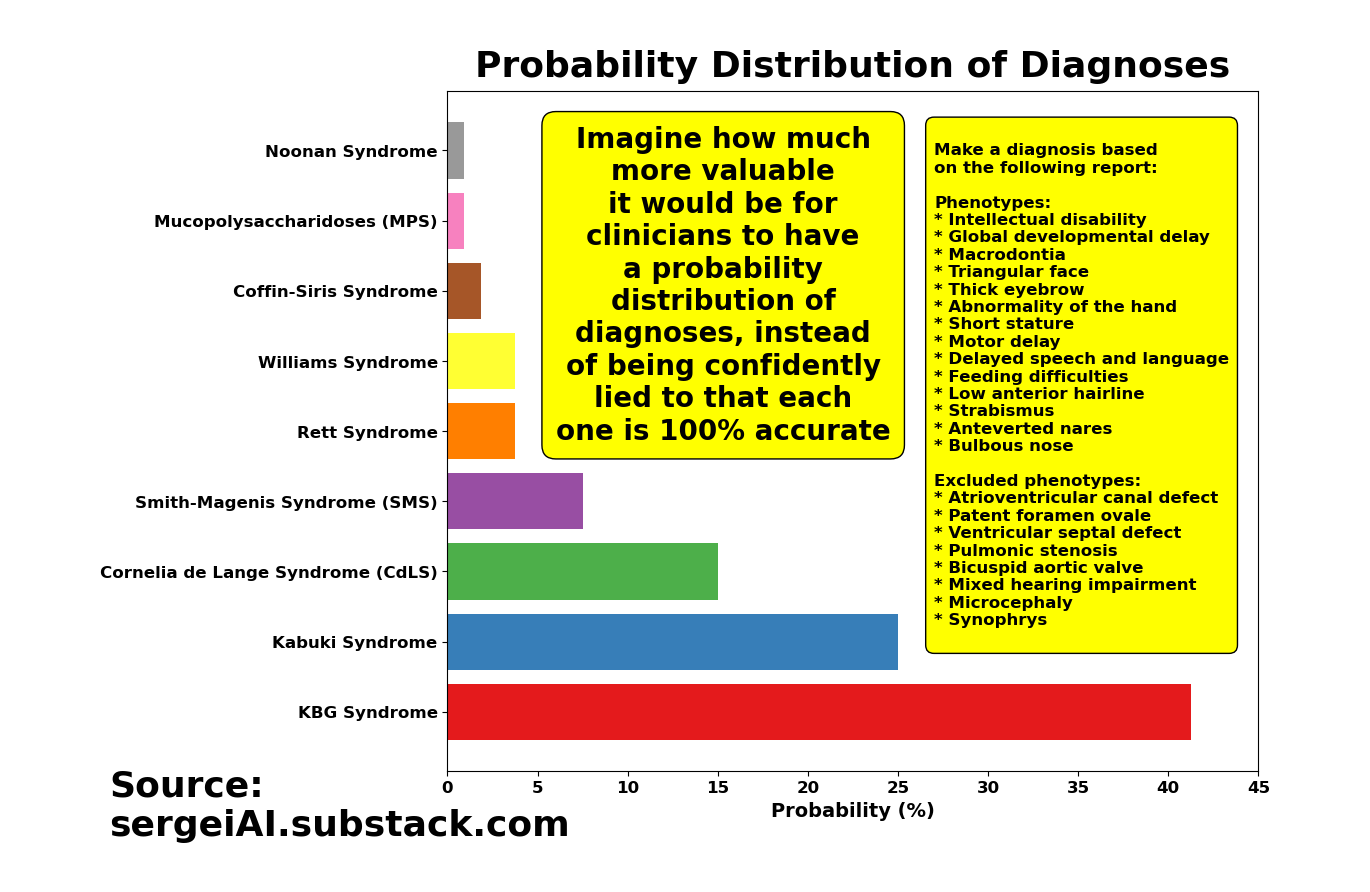
The solution for AI in healthcare is simple: Give clinicians the probabilities of your answers or start developing models that are capable of saying “I don’t know”!
The healthcare industry is fed up with LLMs. The biggest flaw, whether old or new, is that they never say “I don’t know”. They always respond with 100% confidence, even if that response is complete nonsense. This is dangerous. It has to stop.
This irresponsible behavior by OpenAI is making all of us who are trying to use AI for good in healthcare look terrible. More importantly, if the AI industry loses the trust of the medical community, regaining it will be an uphill battle. A recent study by researchers at MIT, the University of Pennsylvania, the University of Georgia, and Amazon shows that negative experiences with AI severely reduce future trust and task performance, particularly in tasks involving collaboration with AI, such as decision-making or predictive tasks. While trust builds gradually as users experience success with AI, a single negative encounter can drastically undermine their perception of the AI’s reliability and hinder human-AI collaboration. (Source: Daehwan Ahn, Abdullah Almaatouq, Monisha Gulabani, Kartik Hosanagar. Impact of Model Interpretability and Outcome Feedback on Trust in AI. Conference on Human Factors in Computing Systems. 2024. DOI: 10.1145/3613904.3642780.)
My plea to Sam Altman, OpenAI, and anyone in AI who genuinely wants to help clinicians and patients:
Be honest about your AI models. Don’t underestimate clinicians’ intelligence. Give us the full distribution of answers. It’s literally one line of code. Please.
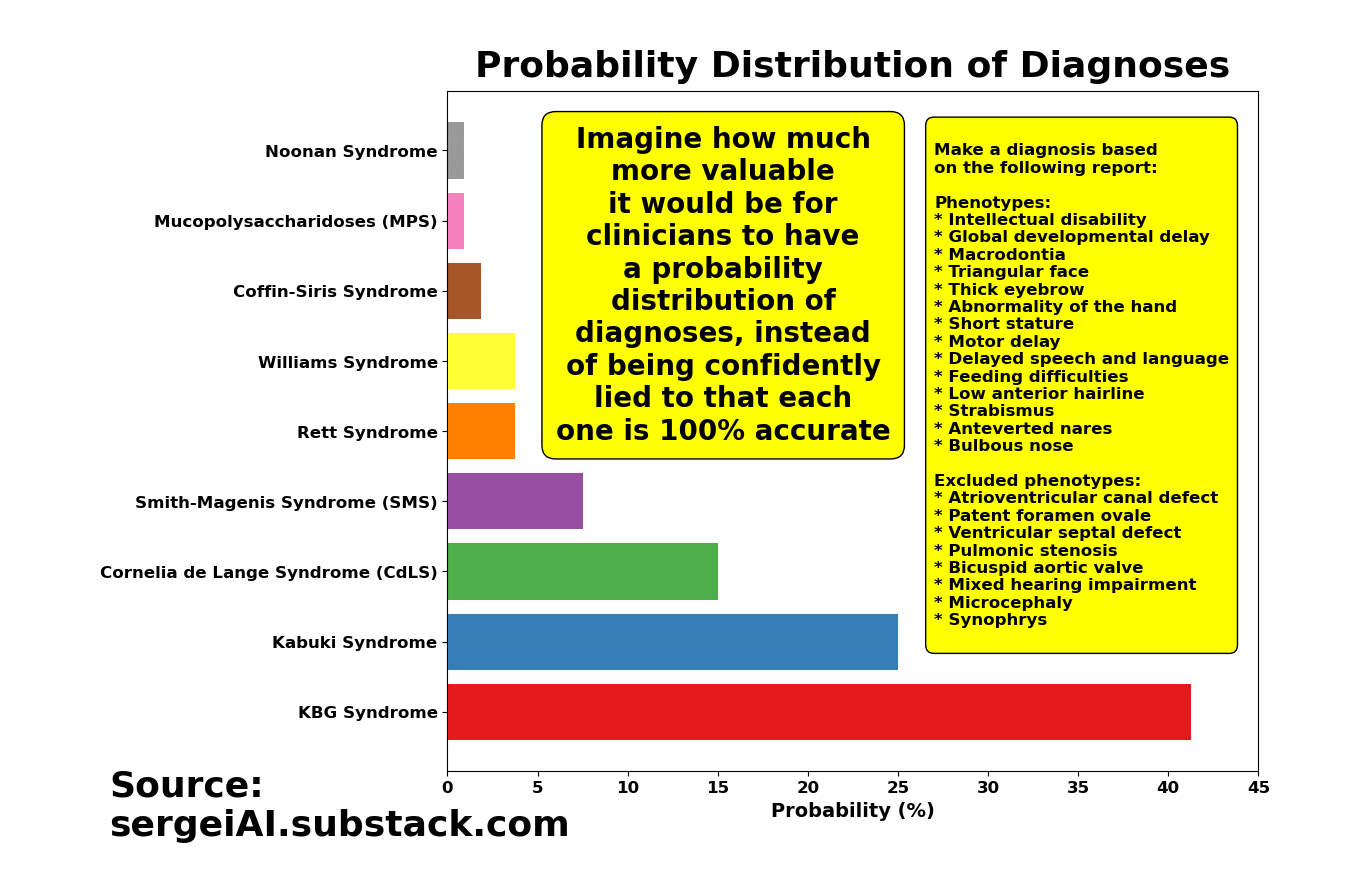
Wouldn’t it be more helpful for physicians to have something like this, instead of being lied to that each time the model is re-run, the new diagnosis is not only 100% accurate, but accompanied by a ‘smooth’ narrative explaining why it’s 100% accurate?
The more facts clinicians have, the more effectively they can treat their patients—and the lower the costs of prevention will be.
Remember: Doctor go to jail. Engineers don’t.
And if OpenAI can’t provide a truthful probabilistic distribution of outcomes, clinicians will gladly drop transformer models and go back to using good ol’ CNNs and RNNs, which can actually say “I don’t know.”
Meanwhile, OpenAI refuses to provide probability distributions:

This is a blatant lie. I can generate the empirical distribution myself by asking ChatGPT the same question 1000 times. I honestly don’t understand the issue. Isn’t the truth, especially when lives are at stake, more important than saying on an earnings call, “Our models are so good, they’re practically error-free”?
Honesty is the best medicine. Right now, AI developers are being dishonest with the medical community.
6. Conclusion
Unfortunately, state-of-the-art AI models, when applied to healthcare, aren’t helping. AI developers refuse to be straightforward with the medical community, and that lack of trust could jeopardize the adoption of AI in healthcare for years, if not decades.
While OpenAI’s new o1 ‘Strawberry’ model shows progress in areas like puzzles and games, where it uses Chain of Thought to improve accuracy, it is far from ready for prime time in healthcare—despite what OpenAI claimed in its o1 release announcement.
The 4o model is confidently misdiagnosing, while o1 is not only confidently misdiagnosing but also cleverly rationalizing the error.
o1 is a smooth talker—a snake oil salesman. It lies right to your face without hesitation.
o1 is dangerous for healthcare.
Here’s my proposal: When it comes to critical areas like medical diagnosis, instead of giving a “Chain of Thought” pitch to justify a misdiagnosis, provide clinicians with data. Right now, clinicians are the final decision-makers in medical diagnosis, and they would welcome any help they can get—especially from state-of-the-art models like OpenAI’s o1 ‘Strawberry.’
Give clinicians probability distributions or teach the model to say, “I don’t know.” In medicine, honesty is worth far more than a good story.
Hi! I believe in fair compensation for every piece of work. So, to those who’ve stepped up as paid subscribers: thank you. 🙏 I don’t have sponsors. I don’t have advertisers. I don’t have bosses. Why? Because I want my research and analyses to remain original and unbiased. However, to continue my work, I rely on support from readers like you. If you’re not a paid subscriber yet and you want my relentless research and analyses like this one to continue for another 12 months, 24 months, 36 months, and more, consider joining the ranks:
👉👉👉👉👉 My name is Sergei Polevikov. I’m an AI researcher and a healthcare AI startup founder. In my newsletter ‘AI Health Uncut’, I combine my knowledge of AI models with my unique skills in analyzing the financial health of digital health companies. Why “Uncut”? Because I never sugarcoat or filter the hard truth. I don’t play games, I don’t work for anyone, and therefore, with your support, I produce the most original, the most unbiased, the most unapologetic research in AI, innovation, and healthcare. Thank you for your support of my work. You’re part of a vibrant community of healthcare AI enthusiasts! Your engagement matters. 🙏🙏🙏🙏🙏

Selling The New o1 'Strawberry' to Healthcare Is a Crime, No Matter What OpenAI Says 🍓