

Humans Still Outperform AI in Reinforcement Learning
What's today? Monday? Ahhh, yeh, that's still true: RLHF is better than RLAIF. Uncle Sam (Altman) is still calling you to fine-tune. So get your thumbs ready. 👍👎


A new paper by Stanford scientists demonstrated that a new technique called RLAIF (Reinforcement Learning from AI Feedback) applied across LLM models in fine-tuning is inferior to the well-established RLHF (Reinforcement Learning from Human Feedback).
What is RLHF? When using ChatGPT, you might notice thumbs up 👍 and thumbs down 👎 icons at the end of each response. Sometimes, ChatGPT asks questions like “Was this response better or worse?” or “Is this conversation helpful so far?” Though it may seem trivial, when even a small fraction of hundreds of millions of users utilize this rating system, they effectively become a free labor force for OpenAI, helping to rank the output of their LLMs using an enormous army of ‘voters’.
Fun fact: when ChatGPT and other LLM chatbots like Claude were developed in 2022 and 2023, the companies used actual human contractors around the world, paying them something like $3 or $5 per hour to ensure the “disturbing” and “harmful” content is not occurring.
The RLHF algorithm is a groundbreaking technique that was introduced by OpenAI researchers in 2022.
Chip Huyen, a renowned AI scientist, gave the best in-depth technical RLHF description I’ve seen so far.
One RLHF caveat discovered recently by researchers from UIUC and Stanford is that there is a relatively easy way for hackers to “undo” all the good stuff that RLHF has generated in terms of safety protections and removal of harmful content. The study showed that the fine-tuning API enables removal of RLHF protections with up to a 95% success rate with as few as 340 examples.
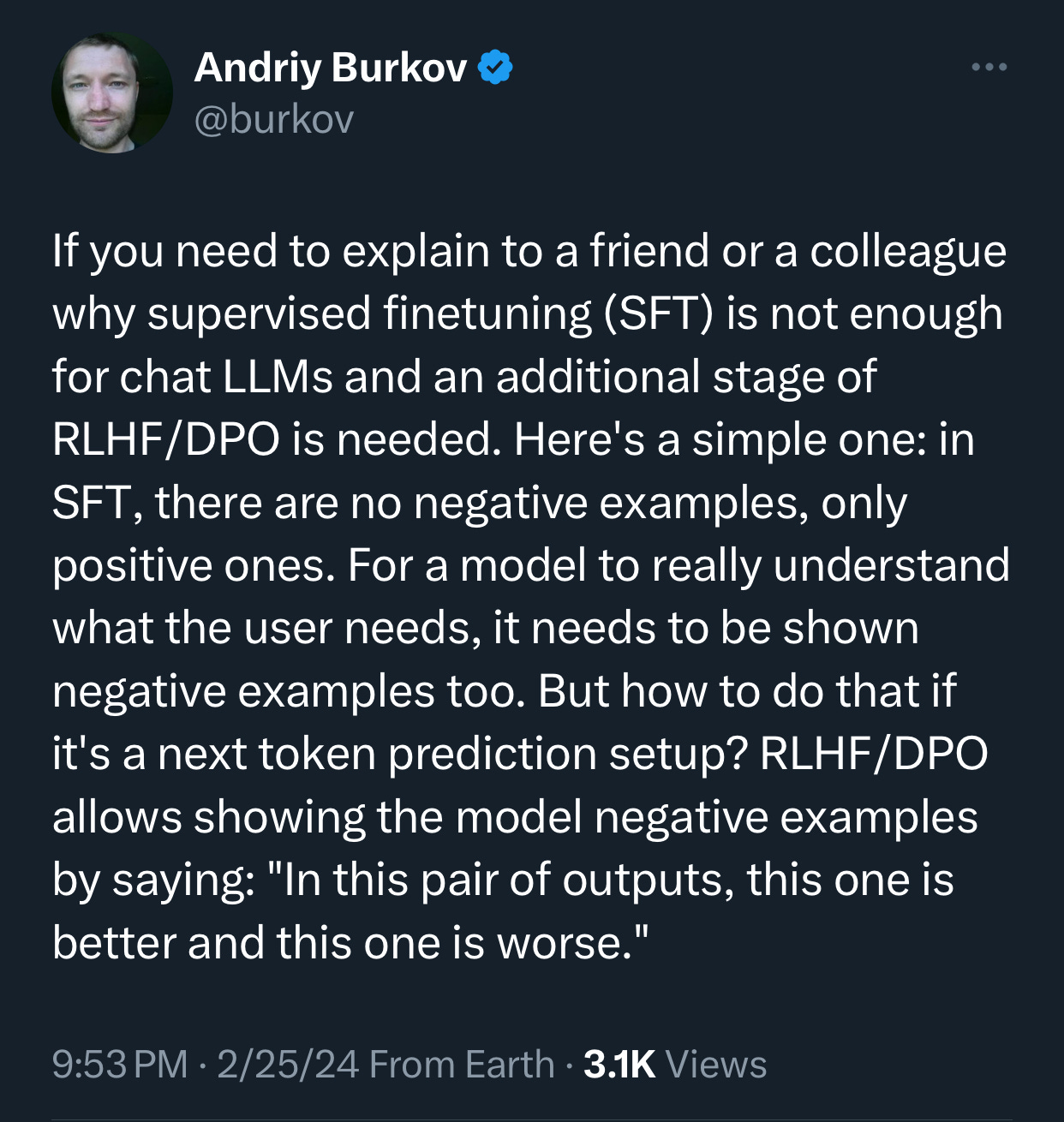
If you need to explain why supervised fine-tuning (SFT) is insufficient for chat LLMs, here’s a simple explanation. SFT is an algorithm that involves training a model on a newly labeled set of examples. However, SFT alone is not enough. An additional stage of RLHF or Direct Preference Optimization (DPO), another human feedback algorithm, is necessary. Here is why. SFT lacks negative examples; it only provides positive ones. For a model to truly understand user needs, it must be exposed to negative examples as well. However, in a next-token prediction setup, how can this be accomplished? RLHF or DPO allow for the introduction of negative examples by indicating which of two outputs is better and which is worse. (Source: Andriy Burkov on X.)
While RLHF has generally yielded incredible results, making ChatGPT increasingly accurate, it has been shown to produce harmful responses, especially when addressing nuanced questions where user expertise may be lacking.
Recently introduced, RLAIF seeks to improve upon RLHF by utilizing AI-generated feedback, employing another LLM to provide this feedback. RLAIF aims to address RLHF’s challenges and offers a less expensive alternative, especially useful in fine-tuning LLM models within narrow fields.
However, RLAIF has set a new ethical precedent and generated criticism from AI ethicists.
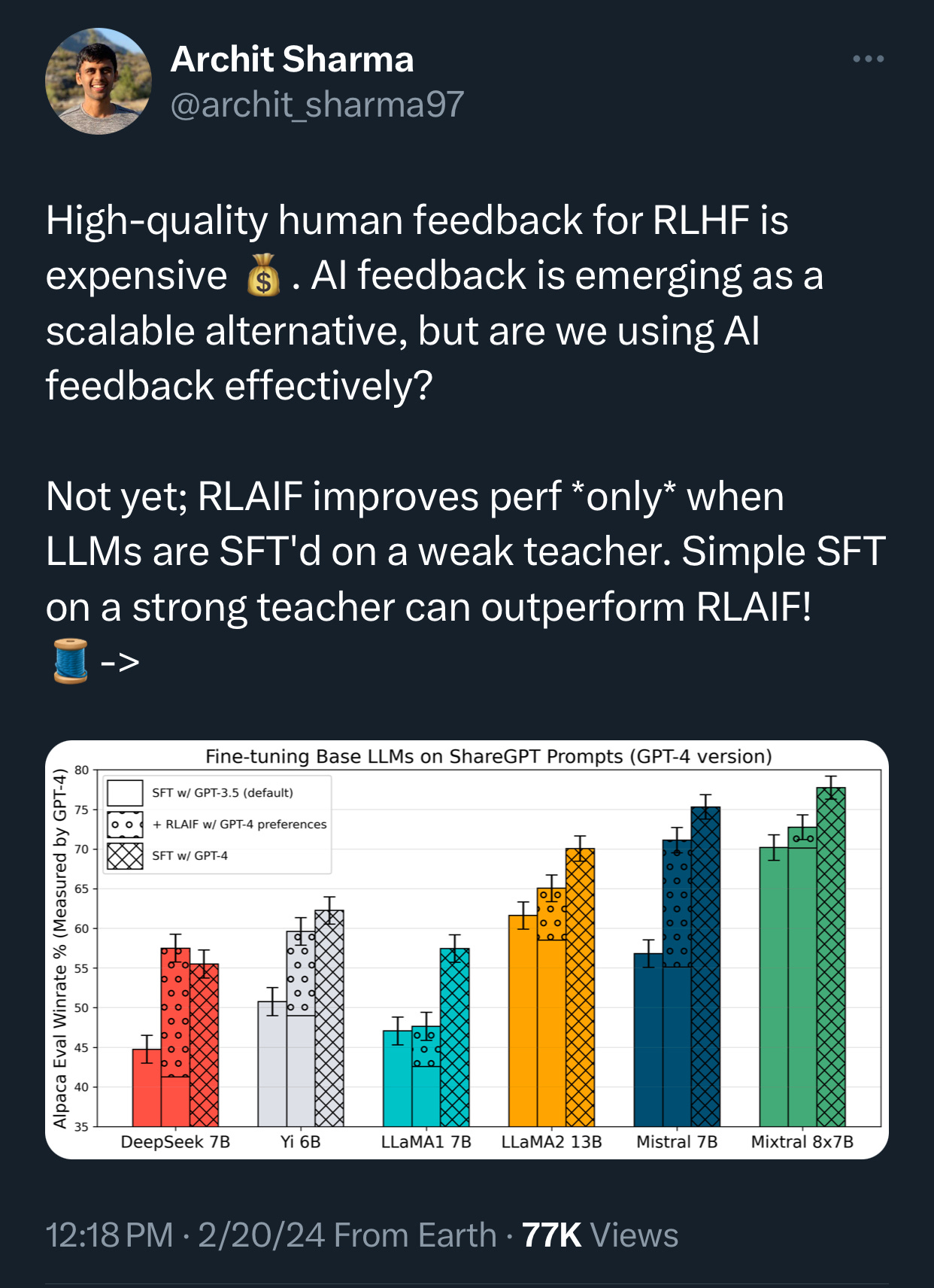
Moreover, this new Stanford study reveals that when RLAIF is generated from stronger “critic” models, such as GPT-4, there is no improvement when used as a complement to SFT on a weaker “teacher” model, such as GPT-3.5. (Source: Archit Sharma on X.)
In addition, in healthcare, particularly in a clinical setting, the application of RLHF is far from trivial. Domain experts, who are highly experienced medical specialists with demanding day jobs, are unlikely to spend their time ranking LLM outputs. And it is certainly challenging for RLAIF to replace RLHF in such scenarios.
Thus, so far, RLAIF has not proven as effective as RLHF.
So, continue being free labor for OpenAI. Uncle Sam (Altman) is still calling you to fine-tune. Get your thumbs ready. 👍👎
👉👉👉👉👉 Hi! My name is Sergei Polevikov. In my newsletter ‘AI Health Uncut’, I combine my knowledge of AI models with my unique skills in analyzing the financial health of digital health companies. Why “Uncut”? Because I never sugarcoat or filter the hard truth. Thank you for your support of my work. You’re part of a vibrant community of healthcare AI enthusiasts! Your engagement matters. 🙏🙏🙏🙏🙏